diff --git a/recognition/arcface_paddle/README.md b/recognition/arcface_paddle/README.md
deleted file mode 120000
index 13c4f96..0000000
--- a/recognition/arcface_paddle/README.md
+++ /dev/null
@@ -1 +0,0 @@
-README_en.md
\ No newline at end of file
diff --git a/recognition/arcface_paddle/README.md b/recognition/arcface_paddle/README.md
new file mode 100644
index 0000000..74f94a6
--- /dev/null
+++ b/recognition/arcface_paddle/README.md
@@ -0,0 +1,260 @@
+# PLSC
+
+## 1. Introduction
+
+[PLSC](https://github.com/PaddlePaddle/PLSC) is an open source Paddle Large Scale Classification Tools, which supports 60 million classes on 8 NVIDIA V100 (32G).
+
+## 2. Environment preparation
+
+### 2.1 Install Paddle from source code
+
+```shell
+
+git clone https://github.com/PaddlePaddle/Paddle.git
+
+cd /path/to/Paddle/
+
+mkdir build && cd build
+
+cmake .. -DWITH_TESTING=ON -DWITH_GPU=ON -DWITH_GOLANG=OFF -DWITH_STYLE_CHECK=ON -DCMAKE_INSTALL_PREFIX=$PWD/output -DWITH_DISTRIBUTE=ON -DCMAKE_BUILD_TYPE=Release -DPY_VERSION=3.7 -DCUDA_ARCH_NAME=All -DPADDLE_VERSION=2.2.0
+
+make -j20 && make install -j20
+
+pip install output/opt/paddle/share/wheels/paddlepaddle_gpu-2.2.0-cp37-cp37m-linux_x86_64.whl
+
+```
+
+### 2.2 Download PLSC
+
+```shell
+git clone https://github.com/PaddlePaddle/PLSC.git
+
+cd /path/to/PLSC/
+```
+
+
+## 3. Data preparation
+
+### 3.1 Download dataset
+
+Download the dataset from [insightface datasets](https://github.com/deepinsight/insightface/tree/master/recognition/_datasets_).
+
+### 3.2 Extract MXNet Dataset to images
+
+```shell
+python tools/mx_recordio_2_images.py --root_dir ms1m-retinaface-t1/ --output_dir MS1M_v3/
+```
+
+After finishing unzipping the dataset, the folder structure is as follows.
+
+```
+arcface_paddle/MS1M_v3
+|_ images
+| |_ 00000001.jpg
+| |_ ...
+| |_ 05179510.jpg
+|_ label.txt
+|_ agedb_30.bin
+|_ cfp_ff.bin
+|_ cfp_fp.bin
+|_ lfw.bin
+```
+
+Label file format is as follows.
+
+```
+# delimiter: "\t"
+# the following the content of label.txt
+images/00000001.jpg 0
+...
+```
+
+If you want to use customed dataset, you can arrange your data according to the above format.
+
+### 3.3 Transform between original image files and bin files
+
+If you want to convert original image files to `bin` files used directly for training process, you can use the following command to finish the conversion.
+
+```shell
+python tools/convert_image_bin.py --image_path="your/input/image/path" --bin_path="your/output/bin/path" --mode="image2bin"
+```
+
+If you want to convert `bin` files to original image files, you can use the following command to finish the conversion.
+
+```shell
+python tools/convert_image_bin.py --image_path="your/input/bin/path" --bin_path="your/output/image/path" --mode="bin2image"
+```
+
+## 4. How to Training
+
+### 4.1 Single node, 8 GPUs:
+
+#### Static Mode
+
+```bash
+sh scripts/train_static.sh
+```
+
+#### Dynamic Mode
+
+```bash
+sh scripts/train_dynamic.sh
+```
+
+
+During training, you can view loss changes in real time through `VisualDL`, For more information, please refer to [VisualDL](https://github.com/PaddlePaddle/VisualDL/).
+
+
+## 5. Model evaluation
+
+The model evaluation process can be started as follows.
+
+#### Static Mode
+
+```bash
+sh scripts/validation_static.sh
+```
+
+#### Dynamic Mode
+
+```bash
+sh scripts/validation_dynamic.sh
+```
+
+## 6. Export model
+PaddlePaddle supports inference using prediction engines. Firstly, you should export inference model.
+
+#### Static Mode
+
+```bash
+sh scripts/export_static.sh
+```
+
+#### Dynamic Mode
+
+```bash
+sh scripts/export_dynamic.sh
+```
+
+We also support export to onnx model, you only need to set `--export_type onnx`.
+
+## 7. Model inference
+
+The model inference process supports paddle save inference model and onnx model.
+
+```bash
+sh scripts/inference.sh
+```
+
+## 8. Model performance
+
+### 8.1 Accuracy on Verification Datasets
+
+**Configuration:**
+ * GPU: 8 NVIDIA Tesla V100 32G
+ * Precison: Pure FP16
+ * BatchSize: 128/1024
+
+| Mode | Datasets | backbone | Ratio | agedb30 | cfp_fp | lfw | log | checkpoint |
+| ------- | :------: | :------- | ----- | :------ | :----- | :--- | :--- | :--- |
+| Static | MS1MV3 | r50 | 0.1 | 0.98317 | 0.98943| 0.99850 | [log](https://raw.githubusercontent.com/GuoxiaWang/plsc_log/master/static/ms1mv3_r50_static_128_fp16_0.1/training.log) | [checkpoint](https://paddle-model-ecology.bj.bcebos.com/model/insight-face/distributed/ms1mv3_r50_static_128_fp16_0.1_epoch_24.tgz) |
+| Static | MS1MV3 | r50 | 1.0 | 0.98283 | 0.98843| 0.99850 | [log](https://raw.githubusercontent.com/GuoxiaWang/plsc_log/master/static/ms1mv3_r50_static_128_fp16_1.0/training.log) | [checkpoint](https://paddle-model-ecology.bj.bcebos.com/model/insight-face/distributed/ms1mv3_r50_static_128_fp16_1.0_epoch_24.tgz) |
+| Dynamic | MS1MV3 | r50 | 0.1 | 0.98333 | 0.98900| 0.99833 | [log](https://raw.githubusercontent.com/GuoxiaWang/plsc_log/master/dynamic/ms1mv3_r50_dynamic_128_fp16_0.1/training.log) | [checkpoint](https://paddle-model-ecology.bj.bcebos.com/model/insight-face/distributed/ms1mv3_r50_dynamic_128_fp16_0.1_eopch_24.tgz) |
+| Dynamic | MS1MV3 | r50 | 1.0 | 0.98317 | 0.98900| 0.99833 | [log](https://raw.githubusercontent.com/GuoxiaWang/plsc_log/master/dynamic/ms1mv3_r50_dynamic_128_fp16_1.0/training.log) | [checkpoint](https://paddle-model-ecology.bj.bcebos.com/model/insight-face/distributed/ms1mv3_r50_dynamic_128_fp16_1.0_eopch_24.tgz) |
+
+
+### 8.2 Maximum Number of Identities
+
+**Configuration:**
+ * GPU: 8 NVIDIA Tesla V100 32G
+ * BatchSize: 64/512
+ * SampleRatio: 0.1
+
+| Mode | Precision | Res50 | Res100 |
+| ------------------------- | --------- | -------- | -------- |
+| Framework1 (static) | AMP | 42000000 | 39000000 |
+| Framework2 (dynamic) | AMP | 30000000 | 29000000 |
+| Paddle (static) | Pure FP16 | 60000000 | 60000000 |
+| Paddle (dynamic) | Pure FP16 | 59000000 | 59000000 |
+
+**Note:** config environment variable ``export FLAGS_allocator_strategy=naive_best_fit``
+
+### 8.3 Throughtput
+
+**Configuration:**
+ * BatchSize: 128/1024
+ * SampleRatio: 0.1
+ * Datasets: MS1MV3
+
+
+
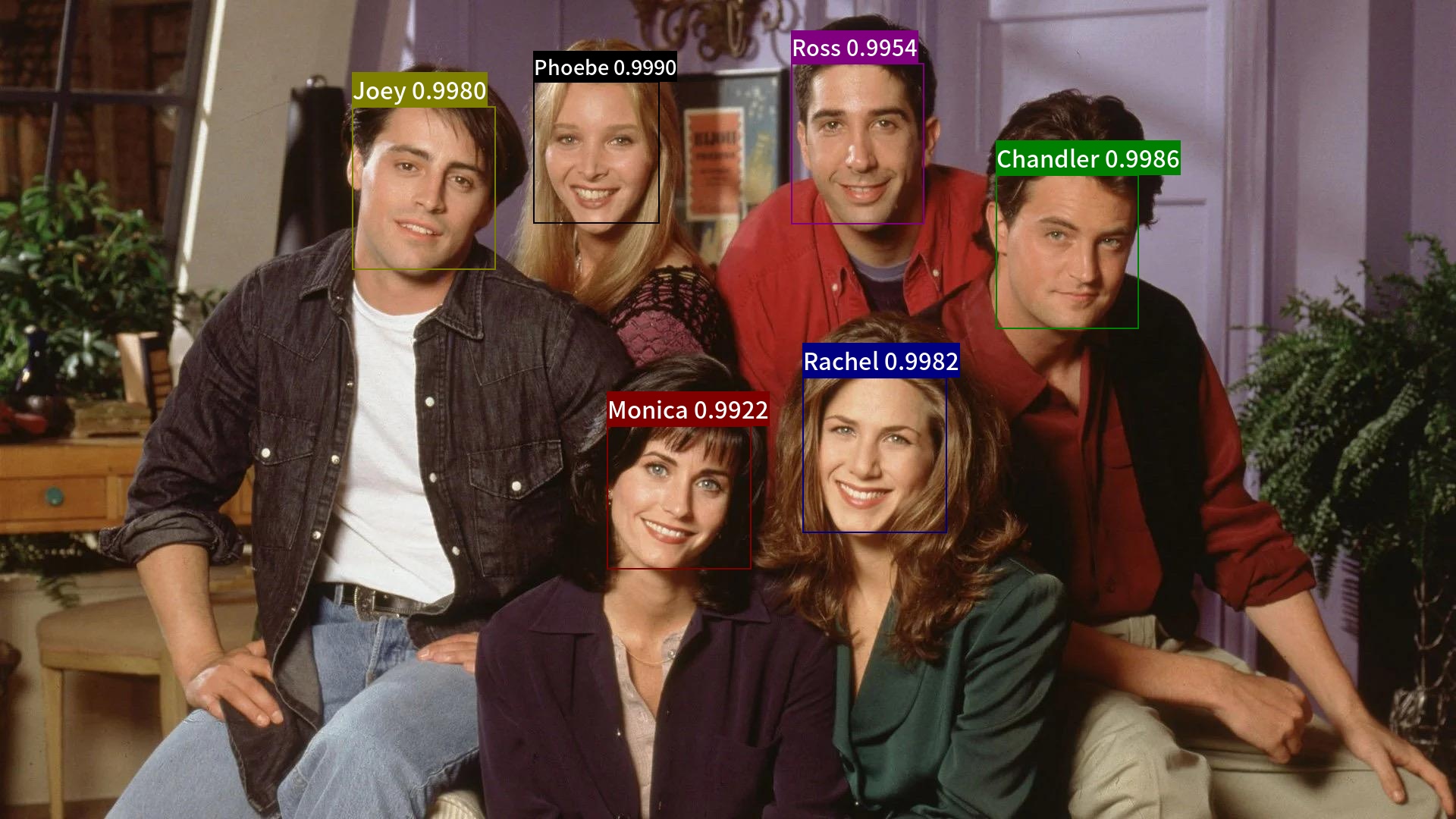
+## 9. Demo
+
+Combined with face detection model, we can complete the face recognition process.
+
+Firstly, use the fllowing commands to download the models.
+
+```bash
+# Create models directory
+mkdir -p models
+
+# Download blazeface face detection model and extract it
+wget https://paddle-model-ecology.bj.bcebos.com/model/insight-face/blazeface_fpn_ssh_1000e_v1.0_infer.tar -P models/
+tar -xzf models/blazeface_fpn_ssh_1000e_v1.0_infer.tar -C models/
+rm -rf models/blazeface_fpn_ssh_1000e_v1.0_infer.tar
+
+# Download static ResNet50 PartialFC 0.1 model and extract it
+wget https://paddle-model-ecology.bj.bcebos.com/model/insight-face/distributed/ms1mv3_r50_static_128_fp16_0.1_epoch_24.tgz -P models/
+tar -xf models/ms1mv3_r50_static_128_fp16_0.1_epoch_24.tgz -C models/
+rm -rf models/ms1mv3_r50_static_128_fp16_0.1_epoch_24.tgz
+
+# Export static save inference model
+python tools/export.py --is_static True --export_type paddle --backbone FresResNet50 --embedding_size 512 --checkpoint_dir models/ms1mv3_r50_static_128_fp16_0.1_epoch_24 --output_dir models/ms1mv3_r50_static_128_fp16_0.1_epoch_24_infer
+rm -rf models/ms1mv3_r50_static_128_fp16_0.1_epoch_24
+```
+
+Then, use the following commands to download the gallery, demo image and font file for visualization. And we generate gallery features.
+
+```bash
+# Download gallery, query and font file
+mkdir -p images/
+git clone https://github.com/littletomatodonkey/insight-face-paddle /tmp/insight-face-paddle
+cp -r /tmp/insight-face-paddle/demo/friends/gallery/ images/
+cp -r /tmp/insight-face-paddle/demo/friends/query/ images/
+mkdir -p assets
+cp /tmp/insight-face-paddle/SourceHanSansCN-Medium.otf assets/
+rm -rf /tmp/insight-face-paddle
+
+# Build index file
+python tools/test_recognition.py \
+ --rec \
+ --rec_model_file_path models/ms1mv3_r50_static_128_fp16_0.1_epoch_24_infer/FresResNet50.pdmodel \
+ --rec_params_file_path models/ms1mv3_r50_static_128_fp16_0.1_epoch_24_infer/FresResNet50.pdiparams \
+ --build_index=images/gallery/index.bin \
+ --img_dir=images/gallery \
+ --label=images/gallery/label.txt
+```
+
+Use the following command to run the whole face recognition demo.
+
+```bash
+# detection + recogniotion process
+python tools/test_recognition.py \
+ --det \
+ --det_model_file_path models/blazeface_fpn_ssh_1000e_v1.0_infer/inference.pdmodel \
+ --det_params_file_path models/blazeface_fpn_ssh_1000e_v1.0_infer/inference.pdiparams \
+ --rec \
+ --rec_model_file_path models/ms1mv3_r50_static_128_fp16_0.1_epoch_24_infer/FresResNet50.pdmodel \
+ --rec_params_file_path models/ms1mv3_r50_static_128_fp16_0.1_epoch_24_infer/FresResNet50.pdiparams \
+ --index=images/gallery/index.bin \
+ --input=images/query/friends2.jpg \
+ --cdd_num 10 \
+ --rec_thresh 0.4 \
+ --output="./output"
+```
+
+The final result is save in folder `output/`, which is shown as follows.
+
+
+

+
-

-
-
-
-
-
-
-