mirror of
https://github.com/deepinsight/insightface.git
synced 2025-12-29 23:52:26 +00:00
a big tree refine
This commit is contained in:
2
.gitignore
vendored
2
.gitignore
vendored
@@ -99,3 +99,5 @@ ENV/
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
|
||||
.DS_Store
|
||||
|
||||
317
README.md
317
README.md
@@ -1,6 +1,10 @@
|
||||
|
||||
# InsightFace: 2D and 3D Face Analysis Project
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="240"/>
|
||||
</div>
|
||||
|
||||
By [Jia Guo](mailto:guojia@gmail.com?subject=[GitHub]%20InsightFace%20Project) and [Jiankang Deng](https://jiankangdeng.github.io/)
|
||||
|
||||
## Top News
|
||||
@@ -21,244 +25,62 @@ The training data containing the annotation (and the models trained with these d
|
||||
|
||||
## Introduction
|
||||
|
||||
InsightFace is an open source 2D&3D deep face analysis toolbox, mainly based on MXNet and PyTorch.
|
||||
[InsightFace](https://insightface.ai) is an open source 2D&3D deep face analysis toolbox, mainly based on PyTorch and MXNet. Please check our [website](https://insightface.ai) for detail.
|
||||
|
||||
The master branch works with **MXNet 1.2 to 1.6**, **PyTorch 1.6+**, with **Python 3.x**.
|
||||
The master branch works with **PyTorch 1.6+** and/or **MXNet=1.6-1.8**, with **Python 3.x**.
|
||||
|
||||
InsightFace efficiently implements a rich variety of state of the art algorithms of face recognition, face detection and face alignment, which optimized for both training and deployment.
|
||||
|
||||
|
||||
## ArcFace Video Demo
|
||||
### ArcFace Video Demo
|
||||
|
||||
[](https://www.youtube.com/watch?v=y-D1tReryGA&t=81s)
|
||||
|
||||
Please click the image to watch the Youtube video. For Bilibili users, click [here](https://www.bilibili.com/video/av38041494?from=search&seid=11501833604850032313).
|
||||
|
||||
## Recent Update
|
||||
|
||||
**`2021-06-05`**: We launch a [Masked Face Recognition Challenge & Workshop](https://github.com/deepinsight/insightface/tree/master/challenges/iccv21-mfr) on ICCV 2021.
|
||||
|
||||
**`2021-05-15`**: We released an efficient high accuracy face detection approach called [SCRFD](https://github.com/deepinsight/insightface/tree/master/detection/scrfd).
|
||||
|
||||
**`2021-04-18`**: We achieved Rank-4th on NIST-FRVT 1:1, see [leaderboard](https://pages.nist.gov/frvt/html/frvt11.html).
|
||||
|
||||
**`2021-03-13`**: We have released our official ArcFace PyTorch implementation, see [here](https://github.com/deepinsight/insightface/tree/master/recognition/arcface_torch).
|
||||
|
||||
**`2021-03-09`**: [Tips](https://github.com/deepinsight/insightface/issues/1426) for training large-scale face recognition model, such as millions of IDs(classes).
|
||||
|
||||
**`2021-02-21`**: We provide a simple face mask renderer [here](https://github.com/deepinsight/insightface/tree/master/recognition/tools) which can be used as a data augmentation tool while training face recognition models.
|
||||
|
||||
**`2021-01-20`**: [OneFlow](https://github.com/Oneflow-Inc/oneflow) based implementation of ArcFace and Partial-FC, [here](https://github.com/deepinsight/insightface/tree/master/recognition/oneflow_face).
|
||||
|
||||
**`2020-10-13`**: A new training method and one large training set(360K IDs) were released [here](https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc) by DeepGlint.
|
||||
|
||||
**`2020-10-09`**: We opened a large scale recognition test benchmark [IFRT](https://github.com/deepinsight/insightface/tree/master/challenges/IFRT)
|
||||
|
||||
**`2020-08-01`**: We released lightweight facial landmark models with fast coordinate regression(106 points). See detail [here](https://github.com/deepinsight/insightface/tree/master/alignment/coordinateReg).
|
||||
|
||||
**`2020-04-27`**: InsightFace pretrained models and MS1M-Arcface are now specified as the only external training dataset, for iQIYI iCartoonFace challenge, see detail [here](http://challenge.ai.iqiyi.com/detail?raceId=5def71b4e9fcf68aef76a75e).
|
||||
|
||||
**`2020.02.21`**: Instant discussion group created on QQ with group-id: 711302608. For English developers, see install tutorial [here](https://github.com/deepinsight/insightface/issues/1069).
|
||||
|
||||
**`2020.02.16`**: RetinaFace now can detect faces with mask, for anti-CoVID19, see detail [here](https://github.com/deepinsight/insightface/tree/master/detection/RetinaFaceAntiCov)
|
||||
|
||||
**`2019.08.10`**: We achieved 2nd place at [WIDER Face Detection Challenge 2019](http://wider-challenge.org/2019.html).
|
||||
|
||||
**`2019.05.30`**: [Presentation at cvmart](https://pan.baidu.com/s/1v9fFHBJ8Q9Kl9Z6GwhbY6A)
|
||||
|
||||
**`2019.04.30`**: Our Face detector ([RetinaFace](https://github.com/deepinsight/insightface/tree/master/detection/RetinaFace)) obtains state-of-the-art results on [the WiderFace dataset](http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html).
|
||||
|
||||
**`2019.04.14`**: We will launch a [Light-weight Face Recognition challenge/workshop](https://github.com/deepinsight/insightface/tree/master/challenges/iccv19-lfr) on ICCV 2019.
|
||||
|
||||
**`2019.04.04`**: Arcface achieved state-of-the-art performance (7/109) on the NIST Face Recognition Vendor Test (FRVT) (1:1 verification)
|
||||
[report](https://www.nist.gov/sites/default/files/documents/2019/04/04/frvt_report_2019_04_04.pdf) (name: Imperial-000 and Imperial-001). Our solution is based on [MS1MV2+DeepGlintAsian, ResNet100, ArcFace loss].
|
||||
|
||||
**`2019.02.08`**: Please check [https://github.com/deepinsight/insightface/tree/master/recognition/ArcFace](https://github.com/deepinsight/insightface/tree/master/recognition/ArcFace) for our parallel training code which can easily and efficiently support one million identities on a single machine (8* 1080ti).
|
||||
|
||||
**`2018.12.13`**: Inference acceleration [TVM-Benchmark](https://github.com/deepinsight/insightface/wiki/TVM-Benchmark).
|
||||
|
||||
**`2018.10.28`**: Light-weight attribute model [Gender-Age](https://github.com/deepinsight/insightface/tree/master/gender-age). About 1MB, 10ms on single CPU core. Gender accuracy 96% on validation set and 4.1 age MAE.
|
||||
|
||||
**`2018.10.16`**: We achieved state-of-the-art performance on [Trillionpairs](http://trillionpairs.deepglint.com/results) (name: nttstar) and [IQIYI_VID](http://challenge.ai.iqiyi.com/detail?raceId=5afc36639689443e8f815f9e) (name: WitcheR).
|
||||
|
||||
|
||||
## Contents
|
||||
[Deep Face Recognition](#deep-face-recognition)
|
||||
- [Introduction](#introduction)
|
||||
- [Training Data](#training-data)
|
||||
- [Train](#train)
|
||||
- [Pretrained Models](#pretrained-models)
|
||||
- [Verification Results On Combined Margin](#verification-results-on-combined-margin)
|
||||
- [Test on MegaFace](#test-on-megaface)
|
||||
- [512-D Feature Embedding](#512-d-feature-embedding)
|
||||
- [Third-party Re-implementation](#third-party-re-implementation)
|
||||
## Projects
|
||||
|
||||
[Face Detection](#face-detection)
|
||||
- [RetinaFace](#retinaface)
|
||||
- [RetinaFaceAntiCov](#retinafaceanticov)
|
||||
The [page](https://insightface.ai/projects) on InsightFace website also describes all supported projects in InsightFace.
|
||||
|
||||
[Face Alignment](#face-alignment)
|
||||
- [DenseUNet](#denseunet)
|
||||
- [CoordinateReg](#coordinatereg)
|
||||
You may also interested in some [challenges](https://insightface.ai/challenges) hold by InsightFace.
|
||||
|
||||
|
||||
[Citation](#citation)
|
||||
|
||||
[Contact](#contact)
|
||||
|
||||
## Deep Face Recognition
|
||||
## Face Recognition
|
||||
|
||||
### Introduction
|
||||
|
||||
In this module, we provide training data, network settings and loss designs for deep face recognition.
|
||||
The training data includes, but not limited to the cleaned MS1M, VGG2 and CASIA-Webface datasets, which were already packed in MXNet binary format.
|
||||
The network backbones include ResNet, MobilefaceNet, MobileNet, InceptionResNet_v2, DenseNet, etc..
|
||||
The loss functions include Softmax, SphereFace, CosineFace, ArcFace, Sub-Center ArcFace and Triplet (Euclidean/Angular) Loss.
|
||||
|
||||
You can check the detail page of our work [ArcFace](https://github.com/deepinsight/insightface/tree/master/recognition/ArcFace)(which accepted in CVPR-2019) and [SubCenter-ArcFace](https://github.com/deepinsight/insightface/tree/master/recognition/SubCenter-ArcFace)(which accepted in ECCV-2020).
|
||||
The supported methods are as follows:
|
||||
|
||||

|
||||
- [x] [ArcFace_mxnet (CVPR'2019)](recognition/arcface_mxnet)
|
||||
- [x] [ArcFace_torch (CVPR'2019)](recognition/arcface_torch)
|
||||
- [x] [SubCenter ArcFace (ECCV'2020)](recognition/subcenter_arcface)
|
||||
- [x] [PartialFC_mxnet (Arxiv'2020)](recognition/partial_fc)
|
||||
- [x] [PartialFC_torch (Arxiv'2020)](recognition/arcface_torch)
|
||||
- [x] [VPL (CVPR'2021)](recognition/vpl)
|
||||
- [x] [OneFlow_face](recognition/oneflow_face)
|
||||
|
||||
Our method, ArcFace, was initially described in an [arXiv technical report](https://arxiv.org/abs/1801.07698). By using this module, you can simply achieve LFW 99.83%+ and Megaface 98%+ by a single model. This module can help researcher/engineer to develop deep face recognition algorithms quickly by only two steps: download the binary dataset and run the training script.
|
||||
|
||||
### Training Data
|
||||
|
||||
All face images are aligned by ficial five landmarks and cropped to 112x112:
|
||||
|
||||
Please check [Dataset-Zoo](https://github.com/deepinsight/insightface/wiki/Dataset-Zoo) for detail information and dataset downloading.
|
||||
Commonly used network backbones are included in most of the methods, such as IResNet, MobilefaceNet, MobileNet, InceptionResNet_v2, DenseNet, etc..
|
||||
|
||||
|
||||
* Please check *recognition/tools/face2rec2.py* on how to build a binary face dataset. You can either choose *MTCNN* or *RetinaFace* to align the faces.
|
||||
### Datasets
|
||||
|
||||
### Train
|
||||
The training data includes, but not limited to the cleaned MS1M, VGG2 and CASIA-Webface datasets, which were already packed in MXNet binary format. Please [dataset](recognition/_dataset_) page for detail.
|
||||
|
||||
1. Install `MXNet` with GPU support (Python 3.X).
|
||||
|
||||
```
|
||||
pip install mxnet-cu101 # which should match your installed cuda version
|
||||
```
|
||||
|
||||
2. Clone the InsightFace repository. We call the directory insightface as *`INSIGHTFACE_ROOT`*.
|
||||
|
||||
```
|
||||
git clone --recursive https://github.com/deepinsight/insightface.git
|
||||
```
|
||||
|
||||
3. Download the training set (`MS1M-Arcface`) and place it in *`$INSIGHTFACE_ROOT/recognition/datasets/`*. Each training dataset includes at least following 6 files:
|
||||
|
||||
```Shell
|
||||
faces_emore/
|
||||
train.idx
|
||||
train.rec
|
||||
property
|
||||
lfw.bin
|
||||
cfp_fp.bin
|
||||
agedb_30.bin
|
||||
```
|
||||
|
||||
The first three files are the training dataset while the last three files are verification sets.
|
||||
|
||||
4. Train deep face recognition models.
|
||||
In this part, we assume you are in the directory *`$INSIGHTFACE_ROOT/recognition/ArcFace/`*.
|
||||
|
||||
Place and edit config file:
|
||||
```Shell
|
||||
cp sample_config.py config.py
|
||||
vim config.py # edit dataset path etc..
|
||||
```
|
||||
|
||||
We give some examples below. Our experiments were conducted on the Tesla P40 GPU.
|
||||
|
||||
(1). Train ArcFace with LResNet100E-IR.
|
||||
|
||||
```Shell
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train.py --network r100 --loss arcface --dataset emore
|
||||
```
|
||||
It will output verification results of *LFW*, *CFP-FP* and *AgeDB-30* every 2000 batches. You can check all options in *config.py*.
|
||||
This model can achieve *LFW 99.83+* and *MegaFace 98.3%+*.
|
||||
|
||||
(2). Train CosineFace with LResNet50E-IR.
|
||||
|
||||
```Shell
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train.py --network r50 --loss cosface --dataset emore
|
||||
```
|
||||
|
||||
(3). Train Softmax with LMobileNet-GAP.
|
||||
|
||||
```Shell
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train.py --network m1 --loss softmax --dataset emore
|
||||
```
|
||||
|
||||
(4). Fine-turn the above Softmax model with Triplet loss.
|
||||
|
||||
```Shell
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train.py --network m1 --loss triplet --lr 0.005 --pretrained ./models/m1-softmax-emore,1
|
||||
```
|
||||
|
||||
(5). Training in model parallel acceleration.
|
||||
|
||||
```Shell
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train_parall.py --network r100 --loss arcface --dataset emore
|
||||
```
|
||||
|
||||
5. Verification results.
|
||||
|
||||
*LResNet100E-IR* network trained on *MS1M-Arcface* dataset with ArcFace loss:
|
||||
|
||||
| Method | LFW(%) | CFP-FP(%) | AgeDB-30(%) |
|
||||
| ------- | ------ | --------- | ----------- |
|
||||
| Ours | 99.80+ | 98.0+ | 98.20+ |
|
||||
### Evaluation
|
||||
|
||||
We provide standard IJB and Megaface evaluation pipelines in [evaluation](recognition/_evaluation_)
|
||||
|
||||
|
||||
### Pretrained Models
|
||||
|
||||
You can use `$INSIGHTFACE_ROOT/recognition/arcface_torch/eval/verification.py` to test all the pre-trained models.
|
||||
|
||||
**Please check [Model-Zoo](https://github.com/deepinsight/insightface/wiki/Model-Zoo) for more pretrained models.**
|
||||
|
||||
|
||||
|
||||
### Verification Results on Combined Margin
|
||||
|
||||
A combined margin method was proposed as a function of target logits value and original `θ`:
|
||||
|
||||
```
|
||||
COM(θ) = cos(m_1*θ+m_2) - m_3
|
||||
```
|
||||
|
||||
For training with `m1=1.0, m2=0.3, m3=0.2`, run following command:
|
||||
```
|
||||
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train.py --network r100 --loss combined --dataset emore
|
||||
```
|
||||
|
||||
Results by using ``MS1M-IBUG(MS1M-V1)``
|
||||
|
||||
| Method | m1 | m2 | m3 | LFW | CFP-FP | AgeDB-30 |
|
||||
| ---------------- | ---- | ---- | ---- | ----- | ------ | -------- |
|
||||
| W&F Norm Softmax | 1 | 0 | 0 | 99.28 | 88.50 | 95.13 |
|
||||
| SphereFace | 1.5 | 0 | 0 | 99.76 | 94.17 | 97.30 |
|
||||
| CosineFace | 1 | 0 | 0.35 | 99.80 | 94.4 | 97.91 |
|
||||
| ArcFace | 1 | 0.5 | 0 | 99.83 | 94.04 | 98.08 |
|
||||
| Combined Margin | 1.2 | 0.4 | 0 | 99.80 | 94.08 | 98.05 |
|
||||
| Combined Margin | 1.1 | 0 | 0.35 | 99.81 | 94.50 | 98.08 |
|
||||
| Combined Margin | 1 | 0.3 | 0.2 | 99.83 | 94.51 | 98.13 |
|
||||
| Combined Margin | 0.9 | 0.4 | 0.15 | 99.83 | 94.20 | 98.16 |
|
||||
|
||||
### Test on MegaFace
|
||||
|
||||
Please check *`$INSIGHTFACE_ROOT/evaluation/megaface/`* to evaluate the model accuracy on Megaface. All aligned images were already provided.
|
||||
|
||||
|
||||
### 512-D Feature Embedding
|
||||
|
||||
In this part, we assume you are in the directory *`$INSIGHTFACE_ROOT/deploy/`*. The input face image should be generally centre cropped. We use *RNet+ONet* of *MTCNN* to further align the image before sending it to the feature embedding network.
|
||||
|
||||
1. Prepare a pre-trained model.
|
||||
2. Put the model under *`$INSIGHTFACE_ROOT/models/`*. For example, *`$INSIGHTFACE_ROOT/models/model-r100-ii`*.
|
||||
3. Run the test script *`$INSIGHTFACE_ROOT/deploy/test.py`*.
|
||||
|
||||
For single cropped face image(112x112), total inference time is only 17ms on our testing server(Intel E5-2660 @ 2.00GHz, Tesla M40, *LResNet34E-IR*).
|
||||
|
||||
### Third-party Re-implementation
|
||||
### Third-party Re-implementation of ArcFace
|
||||
|
||||
- TensorFlow: [InsightFace_TF](https://github.com/auroua/InsightFace_TF)
|
||||
- TensorFlow: [tf-insightface](https://github.com/AIInAi/tf-insightface)
|
||||
@@ -272,39 +94,43 @@ For single cropped face image(112x112), total inference time is only 17ms on our
|
||||
|
||||
## Face Detection
|
||||
|
||||
### RetinaFace
|
||||
### Introduction
|
||||
|
||||
RetinaFace is a practical single-stage [SOTA](http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html) face detector which is initially introduced in [arXiv technical report](https://arxiv.org/abs/1905.00641) and then accepted by [CVPR 2020](https://openaccess.thecvf.com/content_CVPR_2020/html/Deng_RetinaFace_Single-Shot_Multi-Level_Face_Localisation_in_the_Wild_CVPR_2020_paper.html). We provide training code, training dataset, pretrained models and evaluation scripts.
|
||||
|
||||

|
||||
|
||||
Please check [RetinaFace](https://github.com/deepinsight/insightface/tree/master/detection/RetinaFace) for detail.
|
||||
|
||||
### RetinaFaceAntiCov
|
||||
|
||||
RetinaFaceAntiCov is an experimental module to identify face boxes with masks. Please check [RetinaFaceAntiCov](https://github.com/deepinsight/insightface/tree/master/detection/RetinaFaceAntiCov) for detail.
|
||||
|
||||

|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/github/11513D05.jpg" width="640"/>
|
||||
</div>
|
||||
|
||||
In this module, we provide training data with annotation, network settings and loss designs for face detection training, evaluation and inference.
|
||||
|
||||
The supported methods are as follows:
|
||||
|
||||
- [x] [RetinaFace (CVPR'2020)](detection/retinaface)
|
||||
- [x] [SCRFD (Arxiv'2021)](detection/scrfd)
|
||||
|
||||
[RetinaFace](detection/retinaface) is a practical single-stage face detector which is accepted by [CVPR 2020](https://openaccess.thecvf.com/content_CVPR_2020/html/Deng_RetinaFace_Single-Shot_Multi-Level_Face_Localisation_in_the_Wild_CVPR_2020_paper.html). We provide training code, training dataset, pretrained models and evaluation scripts.
|
||||
|
||||
[SCRFD](detection/scrfd) is an efficient high accuracy face detection approach which is initialy described in [Arxiv](https://arxiv.org/abs/2105.04714). We provide an easy-to-use pipeline to train high efficiency face detectors with NAS supporting.
|
||||
|
||||
|
||||
## Face Alignment
|
||||
|
||||
### DenseUNet
|
||||
### Introduction
|
||||
|
||||
Please check the [Menpo](https://github.com/jiankangdeng/MenpoBenchmark) Benchmark and our [Dense U-Net](https://github.com/deepinsight/insightface/tree/master/alignment/heatmapReg) for detail. We also provide other network settings such as classic hourglass. You can find all of training code, training dataset and evaluation scripts there.
|
||||
|
||||
### CoordinateReg
|
||||
|
||||
On the other hand, in contrast to heatmap based approaches, we provide some lightweight facial landmark models with fast coordinate regression. The input of these models is loose cropped face image while the output is the direct landmark coordinates. See detail at [alignment-coordinateReg](https://github.com/deepinsight/insightface/tree/master/alignment/coordinateReg). Now only pretrained models available.
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/nttstar/insightface-resources/blob/master/alignment/images/t1_out.jpg" alt="imagevis" width="800">
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/thumb_sdunet.png" width="600"/>
|
||||
</div>
|
||||
|
||||
In this module, we provide datasets and training/inference pipelines for face alignment.
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/nttstar/insightface-resources/blob/master/alignment/images/C_jiaguo.gif" alt="videovis" width="240">
|
||||
</div>
|
||||
Supported methods:
|
||||
|
||||
- [x] [SDUNets (BMVC'2018)](alignment/heatmap)
|
||||
- [x] [SimpleRegression](alignment/coordinate_reg)
|
||||
|
||||
|
||||
[SDUNets](alignment/heatmap) is a heatmap based method which accepted on [BMVC](http://bmvc2018.org/contents/papers/0051.pdf).
|
||||
|
||||
[SimpleRegression](alignment/coordinate_reg) provides very lightweight facial landmark models with fast coordinate regression. The input of these models is loose cropped face image while the output is the direct landmark coordinates.
|
||||
|
||||
|
||||
## Citation
|
||||
@@ -312,11 +138,34 @@ For single cropped face image(112x112), total inference time is only 17ms on our
|
||||
If you find *InsightFace* useful in your research, please consider to cite the following related papers:
|
||||
|
||||
```
|
||||
@inproceedings{deng2019retinaface,
|
||||
title={RetinaFace: Single-stage Dense Face Localisation in the Wild},
|
||||
author={Deng, Jiankang and Guo, Jia and Yuxiang, Zhou and Jinke Yu and Irene Kotsia and Zafeiriou, Stefanos},
|
||||
booktitle={arxiv},
|
||||
year={2019}
|
||||
|
||||
@article{guo2021sample,
|
||||
title={Sample and Computation Redistribution for Efficient Face Detection},
|
||||
author={Guo, Jia and Deng, Jiankang and Lattas, Alexandros and Zafeiriou, Stefanos},
|
||||
journal={arXiv preprint arXiv:2105.04714},
|
||||
year={2021}
|
||||
}
|
||||
|
||||
@inproceedings{an2020partical_fc,
|
||||
title={Partial FC: Training 10 Million Identities on a Single Machine},
|
||||
author={An, Xiang and Zhu, Xuhan and Xiao, Yang and Wu, Lan and Zhang, Ming and Gao, Yuan and Qin, Bin and
|
||||
Zhang, Debing and Fu Ying},
|
||||
booktitle={Arxiv 2010.05222},
|
||||
year={2020}
|
||||
}
|
||||
|
||||
@inproceedings{deng2020subcenter,
|
||||
title={Sub-center ArcFace: Boosting Face Recognition by Large-scale Noisy Web Faces},
|
||||
author={Deng, Jiankang and Guo, Jia and Liu, Tongliang and Gong, Mingming and Zafeiriou, Stefanos},
|
||||
booktitle={Proceedings of the IEEE Conference on European Conference on Computer Vision},
|
||||
year={2020}
|
||||
}
|
||||
|
||||
@inproceedings{Deng2020CVPR,
|
||||
title = {RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild},
|
||||
author = {Deng, Jiankang and Guo, Jia and Ververas, Evangelos and Kotsia, Irene and Zafeiriou, Stefanos},
|
||||
booktitle = {CVPR},
|
||||
year = {2020}
|
||||
}
|
||||
|
||||
@inproceedings{guo2018stacked,
|
||||
|
||||
@@ -1,4 +1,42 @@
|
||||
You can now find heatmap based approaches under ``heatmapReg`` directory.
|
||||
## Face Alignment
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="240"/>
|
||||
</div>
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
These are the face alignment methods of [InsightFace](https://insightface.ai)
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/thumb_sdunet.png" width="600"/>
|
||||
</div>
|
||||
|
||||
|
||||
### Datasets
|
||||
|
||||
Please refer to [datasets](_datasets_) page for the details of face alignment datasets used for training and evaluation.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Please refer to [evaluation](_evaluation_) page for the details of face alignment evaluation.
|
||||
|
||||
|
||||
## Methods
|
||||
|
||||
|
||||
Supported methods:
|
||||
|
||||
- [x] [SDUNets (BMVC'2018)](heatmap)
|
||||
- [x] [SimpleRegression](coordinate_reg)
|
||||
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
We appreciate all contributions to improve the face alignment model zoo of InsightFace.
|
||||
|
||||
You can now find coordinate regression approaches under ``coordinateReg`` directory.
|
||||
|
||||
|
||||
41
attribute/README.md
Normal file
41
attribute/README.md
Normal file
@@ -0,0 +1,41 @@
|
||||
## Face Alignment
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="320"/>
|
||||
</div>
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
These are the face attribute methods of [InsightFace](https://insightface.ai)
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/github/t1_genderage.jpg" width="600"/>
|
||||
</div>
|
||||
|
||||
|
||||
### Datasets
|
||||
|
||||
Please refer to [datasets](_datasets_) page for the details of face attribute datasets used for training and evaluation.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Please refer to [evaluation](_evaluation_) page for the details of face attribute evaluation.
|
||||
|
||||
|
||||
## Methods
|
||||
|
||||
|
||||
Supported methods:
|
||||
|
||||
- [x] [Gender_Age](gender_age)
|
||||
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
We appreciate all contributions to improve the face attribute model zoo of InsightFace.
|
||||
|
||||
|
||||
@@ -4,25 +4,21 @@ import sys
|
||||
import numpy as np
|
||||
import insightface
|
||||
from insightface.app import FaceAnalysis
|
||||
from insightface.data import get_image as ins_get_image
|
||||
|
||||
assert insightface.__version__>='0.2'
|
||||
|
||||
parser = argparse.ArgumentParser(description='insightface test')
|
||||
parser = argparse.ArgumentParser(description='insightface gender-age test')
|
||||
# general
|
||||
parser.add_argument('--ctx', default=0, type=int, help='ctx id, <0 means using cpu')
|
||||
args = parser.parse_args()
|
||||
|
||||
app = FaceAnalysis(name='antelope')
|
||||
app = FaceAnalysis(allowed_modules=['detection', 'genderage'])
|
||||
app.prepare(ctx_id=args.ctx, det_size=(640,640))
|
||||
|
||||
img = cv2.imread('../sample-images/t1.jpg')
|
||||
img = ins_get_image('t1')
|
||||
faces = app.get(img)
|
||||
assert len(faces)==6
|
||||
rimg = app.draw_on(img, faces)
|
||||
cv2.imwrite("./t1_output.jpg", rimg)
|
||||
print(len(faces))
|
||||
for face in faces:
|
||||
print(face.bbox)
|
||||
print(face.kps)
|
||||
print(face.embedding.shape)
|
||||
print(face.sex, face.age)
|
||||
|
||||
31
challenges/README.md
Normal file
31
challenges/README.md
Normal file
@@ -0,0 +1,31 @@
|
||||
## Challenges
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="240"/>
|
||||
</div>
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
These are challenges hold by [InsightFace](https://insightface.ai)
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/thumb_ifrt.png" width="480"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
## List
|
||||
|
||||
|
||||
Supported methods:
|
||||
|
||||
- [LFR19 (ICCVW'2019)](iccv19-lfr)
|
||||
- [MFR21 (ICCVW'2021)](iccv21-mfr)
|
||||
- [IFRT](ifrt)
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -31,7 +31,7 @@ insightface.challenge@gmail.com
|
||||
|
||||
*For Chinese:*
|
||||
|
||||

|
||||

|
||||
|
||||
*For English:*
|
||||
|
||||
|
||||
@@ -1,8 +0,0 @@
|
||||
InsightFace deployment README
|
||||
---
|
||||
|
||||
For insightface pip-package <= 0.1.5, we use MXNet as inference backend, please download all models from [onedrive](https://1drv.ms/u/s!AswpsDO2toNKrUy0VktHTWgIQ0bn?e=UEF7C4), and put them all under `~/.insightface/models/` directory.
|
||||
|
||||
Starting from insightface>=0.2, we use onnxruntime as inference backend, please download our **antelope** model release from [onedrive](https://1drv.ms/u/s!AswpsDO2toNKrU0ydGgDkrHPdJ3m?e=iVgZox), and put it under `~/.insightface/models/`, so there're onnx models at `~/.insightface/models/antelope/*.onnx`.
|
||||
|
||||
The **antelope** model release contains `ResNet100@Glint360K recognition model` and `SCRFD-10GF detection model`. Please check `test.py` for detail.
|
||||
@@ -1,40 +0,0 @@
|
||||
import sys
|
||||
import os
|
||||
import argparse
|
||||
import onnx
|
||||
import mxnet as mx
|
||||
|
||||
print('mxnet version:', mx.__version__)
|
||||
print('onnx version:', onnx.__version__)
|
||||
#make sure to install onnx-1.2.1
|
||||
#pip uninstall onnx
|
||||
#pip install onnx==1.2.1
|
||||
assert onnx.__version__ == '1.2.1'
|
||||
import numpy as np
|
||||
from mxnet.contrib import onnx as onnx_mxnet
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
description='convert insightface models to onnx')
|
||||
# general
|
||||
parser.add_argument('--prefix',
|
||||
default='./r100-arcface/model',
|
||||
help='prefix to load model.')
|
||||
parser.add_argument('--epoch',
|
||||
default=0,
|
||||
type=int,
|
||||
help='epoch number to load model.')
|
||||
parser.add_argument('--input-shape', default='3,112,112', help='input shape.')
|
||||
parser.add_argument('--output-onnx',
|
||||
default='./r100.onnx',
|
||||
help='path to write onnx model.')
|
||||
args = parser.parse_args()
|
||||
input_shape = (1, ) + tuple([int(x) for x in args.input_shape.split(',')])
|
||||
print('input-shape:', input_shape)
|
||||
|
||||
sym_file = "%s-symbol.json" % args.prefix
|
||||
params_file = "%s-%04d.params" % (args.prefix, args.epoch)
|
||||
assert os.path.exists(sym_file)
|
||||
assert os.path.exists(params_file)
|
||||
converted_model_path = onnx_mxnet.export_model(sym_file, params_file,
|
||||
[input_shape], np.float32,
|
||||
args.output_onnx)
|
||||
@@ -1,67 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import sys
|
||||
import os
|
||||
import argparse
|
||||
import numpy as np
|
||||
import mxnet as mx
|
||||
import cv2
|
||||
import insightface
|
||||
from insightface.utils import face_align
|
||||
|
||||
|
||||
def do_flip(data):
|
||||
for idx in range(data.shape[0]):
|
||||
data[idx, :, :] = np.fliplr(data[idx, :, :])
|
||||
|
||||
|
||||
def get_model(ctx, image_size, prefix, epoch, layer):
|
||||
print('loading', prefix, epoch)
|
||||
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
|
||||
all_layers = sym.get_internals()
|
||||
sym = all_layers[layer + '_output']
|
||||
model = mx.mod.Module(symbol=sym, context=ctx, label_names=None)
|
||||
#model.bind(data_shapes=[('data', (args.batch_size, 3, image_size[0], image_size[1]))], label_shapes=[('softmax_label', (args.batch_size,))])
|
||||
model.bind(data_shapes=[('data', (1, 3, image_size[0], image_size[1]))])
|
||||
model.set_params(arg_params, aux_params)
|
||||
return model
|
||||
|
||||
|
||||
class FaceModel:
|
||||
def __init__(self, ctx_id, model_prefix, model_epoch, use_large_detector=False):
|
||||
if use_large_detector:
|
||||
self.detector = insightface.model_zoo.get_model('retinaface_r50_v1')
|
||||
else:
|
||||
self.detector = insightface.model_zoo.get_model('retinaface_mnet025_v2')
|
||||
self.detector.prepare(ctx_id=ctx_id)
|
||||
if ctx_id>=0:
|
||||
ctx = mx.gpu(ctx_id)
|
||||
else:
|
||||
ctx = mx.cpu()
|
||||
image_size = (112,112)
|
||||
self.model = get_model(ctx, image_size, model_prefix, model_epoch, 'fc1')
|
||||
self.image_size = image_size
|
||||
|
||||
def get_input(self, face_img):
|
||||
bbox, pts5 = self.detector.detect(face_img, threshold=0.8)
|
||||
if bbox.shape[0]==0:
|
||||
return None
|
||||
bbox = bbox[0, 0:4]
|
||||
pts5 = pts5[0, :]
|
||||
nimg = face_align.norm_crop(face_img, pts5)
|
||||
return nimg
|
||||
|
||||
def get_feature(self, aligned):
|
||||
a = cv2.cvtColor(aligned, cv2.COLOR_BGR2RGB)
|
||||
a = np.transpose(a, (2, 0, 1))
|
||||
input_blob = np.expand_dims(a, axis=0)
|
||||
data = mx.nd.array(input_blob)
|
||||
db = mx.io.DataBatch(data=(data, ))
|
||||
self.model.forward(db, is_train=False)
|
||||
emb = self.model.get_outputs()[0].asnumpy()[0]
|
||||
norm = np.sqrt(np.sum(emb*emb)+0.00001)
|
||||
emb /= norm
|
||||
return emb
|
||||
|
||||
@@ -1,32 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import sys
|
||||
import os
|
||||
import argparse
|
||||
import numpy as np
|
||||
import mxnet as mx
|
||||
|
||||
parser = argparse.ArgumentParser(description='face model slim')
|
||||
# general
|
||||
parser.add_argument('--model',
|
||||
default='../models/model-r34-amf/model,60',
|
||||
help='path to load model.')
|
||||
args = parser.parse_args()
|
||||
|
||||
_vec = args.model.split(',')
|
||||
assert len(_vec) == 2
|
||||
prefix = _vec[0]
|
||||
epoch = int(_vec[1])
|
||||
print('loading', prefix, epoch)
|
||||
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
|
||||
all_layers = sym.get_internals()
|
||||
sym = all_layers['fc1_output']
|
||||
dellist = []
|
||||
for k, v in arg_params.iteritems():
|
||||
if k.startswith('fc7'):
|
||||
dellist.append(k)
|
||||
for d in dellist:
|
||||
del arg_params[d]
|
||||
mx.model.save_checkpoint(prefix + "s", 0, sym, arg_params, aux_params)
|
||||
Binary file not shown.
@@ -1,266 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "10",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(2,2)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "16",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "32",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[11, 0], [12, 0], [13, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[14, 0], [15, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(1,1)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "4",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4_2",
|
||||
"inputs": [[16, 0], [17, 0], [18, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(1,1)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "2",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4_1",
|
||||
"inputs": [[16, 0], [20, 0], [21, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxActivation",
|
||||
"param": {"mode": "channel"},
|
||||
"name": "prob1",
|
||||
"inputs": [[22, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
12,
|
||||
13,
|
||||
15,
|
||||
17,
|
||||
18,
|
||||
20,
|
||||
21
|
||||
],
|
||||
"heads": [[19, 0], [23, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,177 +0,0 @@
|
||||
name: "PNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 12
|
||||
input_dim: 12
|
||||
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 10
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 2
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 16
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "conv2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 32
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv4-1"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4-1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 2
|
||||
kernel_size: 1
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv4-2"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 4
|
||||
kernel_size: 1
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv4-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
@@ -1,324 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "28",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "48",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool2",
|
||||
"inputs": [[11, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(2,2)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[12, 0], [13, 0], [14, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[15, 0], [16, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "128"
|
||||
},
|
||||
"name": "conv4",
|
||||
"inputs": [[17, 0], [18, 0], [19, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu4_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu4",
|
||||
"inputs": [[20, 0], [21, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "4"
|
||||
},
|
||||
"name": "conv5_2",
|
||||
"inputs": [[22, 0], [23, 0], [24, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "2"
|
||||
},
|
||||
"name": "conv5_1",
|
||||
"inputs": [[22, 0], [26, 0], [27, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prob1_label",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxOutput",
|
||||
"param": {
|
||||
"grad_scale": "1",
|
||||
"ignore_label": "-1",
|
||||
"multi_output": "False",
|
||||
"normalization": "null",
|
||||
"use_ignore": "False"
|
||||
},
|
||||
"name": "prob1",
|
||||
"inputs": [[28, 0], [29, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
13,
|
||||
14,
|
||||
16,
|
||||
18,
|
||||
19,
|
||||
21,
|
||||
23,
|
||||
24,
|
||||
26,
|
||||
27,
|
||||
29
|
||||
],
|
||||
"heads": [[25, 0], [30, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,228 +0,0 @@
|
||||
name: "RNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 24
|
||||
input_dim: 24
|
||||
|
||||
|
||||
##########################
|
||||
######################
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
propagate_down: true
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
propagate_down: true
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
####################################
|
||||
|
||||
##################################
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
propagate_down: true
|
||||
}
|
||||
###############################
|
||||
|
||||
###############################
|
||||
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 128
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv5-1"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5-1"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
#kernel_size: 1
|
||||
#stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv5-2"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4
|
||||
#kernel_size: 1
|
||||
#stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv5-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
@@ -1,418 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "32",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool2",
|
||||
"inputs": [[11, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[12, 0], [13, 0], [14, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[15, 0], [16, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(2,2)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool3",
|
||||
"inputs": [[17, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(2,2)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "128",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4",
|
||||
"inputs": [[18, 0], [19, 0], [20, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu4_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu4",
|
||||
"inputs": [[21, 0], [22, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "256"
|
||||
},
|
||||
"name": "conv5",
|
||||
"inputs": [[23, 0], [24, 0], [25, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu5_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu5",
|
||||
"inputs": [[26, 0], [27, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "10"
|
||||
},
|
||||
"name": "conv6_3",
|
||||
"inputs": [[28, 0], [29, 0], [30, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "4"
|
||||
},
|
||||
"name": "conv6_2",
|
||||
"inputs": [[28, 0], [32, 0], [33, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "2"
|
||||
},
|
||||
"name": "conv6_1",
|
||||
"inputs": [[28, 0], [35, 0], [36, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prob1_label",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxOutput",
|
||||
"param": {
|
||||
"grad_scale": "1",
|
||||
"ignore_label": "-1",
|
||||
"multi_output": "False",
|
||||
"normalization": "null",
|
||||
"use_ignore": "False"
|
||||
},
|
||||
"name": "prob1",
|
||||
"inputs": [[37, 0], [38, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
13,
|
||||
14,
|
||||
16,
|
||||
19,
|
||||
20,
|
||||
22,
|
||||
24,
|
||||
25,
|
||||
27,
|
||||
29,
|
||||
30,
|
||||
32,
|
||||
33,
|
||||
35,
|
||||
36,
|
||||
38
|
||||
],
|
||||
"heads": [[31, 0], [34, 0], [39, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,294 +0,0 @@
|
||||
name: "ONet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 48
|
||||
input_dim: 48
|
||||
##################################
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 32
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "prelu2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "pool3"
|
||||
type: "Pooling"
|
||||
bottom: "conv3"
|
||||
top: "pool3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 2
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "pool3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 128
|
||||
kernel_size: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 3
|
||||
num_output: 256
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "drop5"
|
||||
type: "Dropout"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.25
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu5"
|
||||
type: "PReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv6-1"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv6-2"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 4
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv6-3"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 10
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv6-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
File diff suppressed because it is too large
Load Diff
Binary file not shown.
@@ -1,995 +0,0 @@
|
||||
name: "LNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 15
|
||||
input_dim: 24
|
||||
input_dim: 24
|
||||
|
||||
layer {
|
||||
name: "slicer_data"
|
||||
type: "Slice"
|
||||
bottom: "data"
|
||||
top: "data241"
|
||||
top: "data242"
|
||||
top: "data243"
|
||||
top: "data244"
|
||||
top: "data245"
|
||||
slice_param {
|
||||
axis: 1
|
||||
slice_point: 3
|
||||
slice_point: 6
|
||||
slice_point: 9
|
||||
slice_point: 12
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1_1"
|
||||
type: "Convolution"
|
||||
bottom: "data241"
|
||||
top: "conv1_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_1"
|
||||
top: "conv1_1"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_1"
|
||||
top: "pool1_1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_1"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_1"
|
||||
top: "conv2_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_1"
|
||||
top: "conv2_1"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_1"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_1"
|
||||
top: "pool2_1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_1"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_1"
|
||||
top: "conv3_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_1"
|
||||
top: "conv3_1"
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_2"
|
||||
type: "Convolution"
|
||||
bottom: "data242"
|
||||
top: "conv1_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_2"
|
||||
top: "conv1_2"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_2"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_2"
|
||||
top: "pool1_2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_2"
|
||||
top: "conv2_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_2"
|
||||
top: "conv2_2"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_2"
|
||||
top: "pool2_2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_2"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_2"
|
||||
top: "conv3_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_2"
|
||||
top: "conv3_2"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_3"
|
||||
type: "Convolution"
|
||||
bottom: "data243"
|
||||
top: "conv1_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_3"
|
||||
top: "conv1_3"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_3"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_3"
|
||||
top: "pool1_3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_3"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_3"
|
||||
top: "conv2_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_3"
|
||||
top: "conv2_3"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_3"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_3"
|
||||
top: "pool2_3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_3"
|
||||
top: "conv3_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_3"
|
||||
top: "conv3_3"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_4"
|
||||
type: "Convolution"
|
||||
bottom: "data244"
|
||||
top: "conv1_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_4"
|
||||
top: "conv1_4"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_4"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_4"
|
||||
top: "pool1_4"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_4"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_4"
|
||||
top: "conv2_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_4"
|
||||
top: "conv2_4"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_4"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_4"
|
||||
top: "pool2_4"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_4"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_4"
|
||||
top: "conv3_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_4"
|
||||
top: "conv3_4"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_5"
|
||||
type: "Convolution"
|
||||
bottom: "data245"
|
||||
top: "conv1_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_5"
|
||||
top: "conv1_5"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_5"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_5"
|
||||
top: "pool1_5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_5"
|
||||
top: "conv2_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_5"
|
||||
top: "conv2_5"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_5"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_5"
|
||||
top: "pool2_5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_5"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_5"
|
||||
top: "conv3_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_5"
|
||||
top: "conv3_5"
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "concat"
|
||||
bottom: "conv3_1"
|
||||
bottom: "conv3_2"
|
||||
bottom: "conv3_3"
|
||||
bottom: "conv3_4"
|
||||
bottom: "conv3_5"
|
||||
top: "conv3"
|
||||
type: "Concat"
|
||||
concat_param {
|
||||
axis: 1
|
||||
}
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "fc4"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv3"
|
||||
top: "fc4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 256
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "fc4"
|
||||
top: "fc4"
|
||||
}
|
||||
############################
|
||||
layer {
|
||||
name: "fc4_1"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_1"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_1"
|
||||
top: "fc4_1"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_1"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_1"
|
||||
top: "fc5_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_2"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_2"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_2"
|
||||
top: "fc4_2"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_2"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_2"
|
||||
top: "fc5_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_3"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_3"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_3"
|
||||
top: "fc4_3"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_3"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_3"
|
||||
top: "fc5_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_4"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_4"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_4"
|
||||
top: "fc4_4"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_4"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_4"
|
||||
top: "fc5_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_5"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_5"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_5"
|
||||
top: "fc4_5"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_5"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_5"
|
||||
top: "fc5_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
|
||||
@@ -1,864 +0,0 @@
|
||||
# coding: utf-8
|
||||
import os
|
||||
import mxnet as mx
|
||||
import numpy as np
|
||||
import math
|
||||
import cv2
|
||||
from multiprocessing import Pool
|
||||
from itertools import repeat
|
||||
try:
|
||||
from itertools import izip
|
||||
except ImportError:
|
||||
izip = zip
|
||||
|
||||
def nms(boxes, overlap_threshold, mode='Union'):
|
||||
"""
|
||||
non max suppression
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
box: numpy array n x 5
|
||||
input bbox array
|
||||
overlap_threshold: float number
|
||||
threshold of overlap
|
||||
mode: float number
|
||||
how to compute overlap ratio, 'Union' or 'Min'
|
||||
Returns:
|
||||
-------
|
||||
index array of the selected bbox
|
||||
"""
|
||||
# if there are no boxes, return an empty list
|
||||
if len(boxes) == 0:
|
||||
return []
|
||||
|
||||
# if the bounding boxes integers, convert them to floats
|
||||
if boxes.dtype.kind == "i":
|
||||
boxes = boxes.astype("float")
|
||||
|
||||
# initialize the list of picked indexes
|
||||
pick = []
|
||||
|
||||
# grab the coordinates of the bounding boxes
|
||||
x1, y1, x2, y2, score = [boxes[:, i] for i in range(5)]
|
||||
|
||||
area = (x2 - x1 + 1) * (y2 - y1 + 1)
|
||||
idxs = np.argsort(score)
|
||||
|
||||
# keep looping while some indexes still remain in the indexes list
|
||||
while len(idxs) > 0:
|
||||
# grab the last index in the indexes list and add the index value to the list of picked indexes
|
||||
last = len(idxs) - 1
|
||||
i = idxs[last]
|
||||
pick.append(i)
|
||||
|
||||
xx1 = np.maximum(x1[i], x1[idxs[:last]])
|
||||
yy1 = np.maximum(y1[i], y1[idxs[:last]])
|
||||
xx2 = np.minimum(x2[i], x2[idxs[:last]])
|
||||
yy2 = np.minimum(y2[i], y2[idxs[:last]])
|
||||
|
||||
# compute the width and height of the bounding box
|
||||
w = np.maximum(0, xx2 - xx1 + 1)
|
||||
h = np.maximum(0, yy2 - yy1 + 1)
|
||||
|
||||
inter = w * h
|
||||
if mode == 'Min':
|
||||
overlap = inter / np.minimum(area[i], area[idxs[:last]])
|
||||
else:
|
||||
overlap = inter / (area[i] + area[idxs[:last]] - inter)
|
||||
|
||||
# delete all indexes from the index list that have
|
||||
idxs = np.delete(
|
||||
idxs,
|
||||
np.concatenate(([last], np.where(overlap > overlap_threshold)[0])))
|
||||
|
||||
return pick
|
||||
|
||||
|
||||
def adjust_input(in_data):
|
||||
"""
|
||||
adjust the input from (h, w, c) to ( 1, c, h, w) for network input
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
in_data: numpy array of shape (h, w, c)
|
||||
input data
|
||||
Returns:
|
||||
-------
|
||||
out_data: numpy array of shape (1, c, h, w)
|
||||
reshaped array
|
||||
"""
|
||||
if in_data.dtype is not np.dtype('float32'):
|
||||
out_data = in_data.astype(np.float32)
|
||||
else:
|
||||
out_data = in_data
|
||||
|
||||
out_data = out_data.transpose((2, 0, 1))
|
||||
out_data = np.expand_dims(out_data, 0)
|
||||
out_data = (out_data - 127.5) * 0.0078125
|
||||
return out_data
|
||||
|
||||
|
||||
def generate_bbox(map, reg, scale, threshold):
|
||||
"""
|
||||
generate bbox from feature map
|
||||
Parameters:
|
||||
----------
|
||||
map: numpy array , n x m x 1
|
||||
detect score for each position
|
||||
reg: numpy array , n x m x 4
|
||||
bbox
|
||||
scale: float number
|
||||
scale of this detection
|
||||
threshold: float number
|
||||
detect threshold
|
||||
Returns:
|
||||
-------
|
||||
bbox array
|
||||
"""
|
||||
stride = 2
|
||||
cellsize = 12
|
||||
|
||||
t_index = np.where(map > threshold)
|
||||
|
||||
# find nothing
|
||||
if t_index[0].size == 0:
|
||||
return np.array([])
|
||||
|
||||
dx1, dy1, dx2, dy2 = [reg[0, i, t_index[0], t_index[1]] for i in range(4)]
|
||||
|
||||
reg = np.array([dx1, dy1, dx2, dy2])
|
||||
score = map[t_index[0], t_index[1]]
|
||||
boundingbox = np.vstack([
|
||||
np.round((stride * t_index[1] + 1) / scale),
|
||||
np.round((stride * t_index[0] + 1) / scale),
|
||||
np.round((stride * t_index[1] + 1 + cellsize) / scale),
|
||||
np.round((stride * t_index[0] + 1 + cellsize) / scale), score, reg
|
||||
])
|
||||
|
||||
return boundingbox.T
|
||||
|
||||
|
||||
def detect_first_stage(img, net, scale, threshold):
|
||||
"""
|
||||
run PNet for first stage
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order
|
||||
input image
|
||||
scale: float number
|
||||
how much should the input image scale
|
||||
net: PNet
|
||||
worker
|
||||
Returns:
|
||||
-------
|
||||
total_boxes : bboxes
|
||||
"""
|
||||
height, width, _ = img.shape
|
||||
hs = int(math.ceil(height * scale))
|
||||
ws = int(math.ceil(width * scale))
|
||||
|
||||
im_data = cv2.resize(img, (ws, hs))
|
||||
|
||||
# adjust for the network input
|
||||
input_buf = adjust_input(im_data)
|
||||
output = net.predict(input_buf)
|
||||
boxes = generate_bbox(output[1][0, 1, :, :], output[0], scale, threshold)
|
||||
|
||||
if boxes.size == 0:
|
||||
return None
|
||||
|
||||
# nms
|
||||
pick = nms(boxes[:, 0:5], 0.5, mode='Union')
|
||||
boxes = boxes[pick]
|
||||
return boxes
|
||||
|
||||
|
||||
def detect_first_stage_warpper(args):
|
||||
return detect_first_stage(*args)
|
||||
|
||||
class MtcnnDetector(object):
|
||||
"""
|
||||
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Neural Networks
|
||||
see https://github.com/kpzhang93/MTCNN_face_detection_alignment
|
||||
this is a mxnet version
|
||||
"""
|
||||
def __init__(self,
|
||||
model_folder='.',
|
||||
minsize=20,
|
||||
threshold=[0.6, 0.7, 0.8],
|
||||
factor=0.709,
|
||||
num_worker=1,
|
||||
accurate_landmark=False,
|
||||
ctx=mx.cpu()):
|
||||
"""
|
||||
Initialize the detector
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
model_folder : string
|
||||
path for the models
|
||||
minsize : float number
|
||||
minimal face to detect
|
||||
threshold : float number
|
||||
detect threshold for 3 stages
|
||||
factor: float number
|
||||
scale factor for image pyramid
|
||||
num_worker: int number
|
||||
number of processes we use for first stage
|
||||
accurate_landmark: bool
|
||||
use accurate landmark localization or not
|
||||
|
||||
"""
|
||||
self.num_worker = num_worker
|
||||
self.accurate_landmark = accurate_landmark
|
||||
|
||||
# load 4 models from folder
|
||||
models = ['det1', 'det2', 'det3', 'det4']
|
||||
models = [os.path.join(model_folder, f) for f in models]
|
||||
|
||||
self.PNets = []
|
||||
for i in range(num_worker):
|
||||
workner_net = mx.model.FeedForward.load(models[0], 1, ctx=ctx)
|
||||
self.PNets.append(workner_net)
|
||||
|
||||
#self.Pool = Pool(num_worker)
|
||||
|
||||
self.RNet = mx.model.FeedForward.load(models[1], 1, ctx=ctx)
|
||||
self.ONet = mx.model.FeedForward.load(models[2], 1, ctx=ctx)
|
||||
self.LNet = mx.model.FeedForward.load(models[3], 1, ctx=ctx)
|
||||
|
||||
self.minsize = float(minsize)
|
||||
self.factor = float(factor)
|
||||
self.threshold = threshold
|
||||
|
||||
def convert_to_square(self, bbox):
|
||||
"""
|
||||
convert bbox to square
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bbox: numpy array , shape n x 5
|
||||
input bbox
|
||||
|
||||
Returns:
|
||||
-------
|
||||
square bbox
|
||||
"""
|
||||
square_bbox = bbox.copy()
|
||||
|
||||
h = bbox[:, 3] - bbox[:, 1] + 1
|
||||
w = bbox[:, 2] - bbox[:, 0] + 1
|
||||
max_side = np.maximum(h, w)
|
||||
square_bbox[:, 0] = bbox[:, 0] + w * 0.5 - max_side * 0.5
|
||||
square_bbox[:, 1] = bbox[:, 1] + h * 0.5 - max_side * 0.5
|
||||
square_bbox[:, 2] = square_bbox[:, 0] + max_side - 1
|
||||
square_bbox[:, 3] = square_bbox[:, 1] + max_side - 1
|
||||
return square_bbox
|
||||
|
||||
def calibrate_box(self, bbox, reg):
|
||||
"""
|
||||
calibrate bboxes
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bbox: numpy array, shape n x 5
|
||||
input bboxes
|
||||
reg: numpy array, shape n x 4
|
||||
bboxex adjustment
|
||||
|
||||
Returns:
|
||||
-------
|
||||
bboxes after refinement
|
||||
|
||||
"""
|
||||
w = bbox[:, 2] - bbox[:, 0] + 1
|
||||
w = np.expand_dims(w, 1)
|
||||
h = bbox[:, 3] - bbox[:, 1] + 1
|
||||
h = np.expand_dims(h, 1)
|
||||
reg_m = np.hstack([w, h, w, h])
|
||||
aug = reg_m * reg
|
||||
bbox[:, 0:4] = bbox[:, 0:4] + aug
|
||||
return bbox
|
||||
|
||||
def pad(self, bboxes, w, h):
|
||||
"""
|
||||
pad the the bboxes, alse restrict the size of it
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bboxes: numpy array, n x 5
|
||||
input bboxes
|
||||
w: float number
|
||||
width of the input image
|
||||
h: float number
|
||||
height of the input image
|
||||
Returns :
|
||||
------s
|
||||
dy, dx : numpy array, n x 1
|
||||
start point of the bbox in target image
|
||||
edy, edx : numpy array, n x 1
|
||||
end point of the bbox in target image
|
||||
y, x : numpy array, n x 1
|
||||
start point of the bbox in original image
|
||||
ex, ex : numpy array, n x 1
|
||||
end point of the bbox in original image
|
||||
tmph, tmpw: numpy array, n x 1
|
||||
height and width of the bbox
|
||||
|
||||
"""
|
||||
tmpw, tmph = bboxes[:, 2] - bboxes[:, 0] + 1, bboxes[:,
|
||||
3] - bboxes[:,
|
||||
1] + 1
|
||||
num_box = bboxes.shape[0]
|
||||
|
||||
dx, dy = np.zeros((num_box, )), np.zeros((num_box, ))
|
||||
edx, edy = tmpw.copy() - 1, tmph.copy() - 1
|
||||
|
||||
x, y, ex, ey = bboxes[:, 0], bboxes[:, 1], bboxes[:, 2], bboxes[:, 3]
|
||||
|
||||
tmp_index = np.where(ex > w - 1)
|
||||
edx[tmp_index] = tmpw[tmp_index] + w - 2 - ex[tmp_index]
|
||||
ex[tmp_index] = w - 1
|
||||
|
||||
tmp_index = np.where(ey > h - 1)
|
||||
edy[tmp_index] = tmph[tmp_index] + h - 2 - ey[tmp_index]
|
||||
ey[tmp_index] = h - 1
|
||||
|
||||
tmp_index = np.where(x < 0)
|
||||
dx[tmp_index] = 0 - x[tmp_index]
|
||||
x[tmp_index] = 0
|
||||
|
||||
tmp_index = np.where(y < 0)
|
||||
dy[tmp_index] = 0 - y[tmp_index]
|
||||
y[tmp_index] = 0
|
||||
|
||||
return_list = [dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph]
|
||||
return_list = [item.astype(np.int32) for item in return_list]
|
||||
|
||||
return return_list
|
||||
|
||||
def slice_index(self, number):
|
||||
"""
|
||||
slice the index into (n,n,m), m < n
|
||||
Parameters:
|
||||
----------
|
||||
number: int number
|
||||
number
|
||||
"""
|
||||
def chunks(l, n):
|
||||
"""Yield successive n-sized chunks from l."""
|
||||
for i in range(0, len(l), n):
|
||||
yield l[i:i + n]
|
||||
|
||||
num_list = range(number)
|
||||
return list(chunks(num_list, self.num_worker))
|
||||
|
||||
def detect_face_limited(self, img, det_type=2):
|
||||
height, width, _ = img.shape
|
||||
if det_type >= 2:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 24, 24) is the input shape for RNet
|
||||
input_buf = np.zeros((num_box, 3, 24, 24), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
||||
tmp[dy[i]:edy[i] + 1,
|
||||
dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (24, 24)))
|
||||
|
||||
output = self.RNet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[1][:, 1] > self.threshold[1])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[1][passed, 1].reshape((-1, ))
|
||||
reg = output[0][passed]
|
||||
|
||||
# nms
|
||||
pick = nms(total_boxes, 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
total_boxes = self.calibrate_box(total_boxes, reg[pick])
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
else:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
num_box = total_boxes.shape[0]
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 48, 48) is the input shape for ONet
|
||||
input_buf = np.zeros((num_box, 3, 48, 48), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.float32)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (48, 48)))
|
||||
|
||||
output = self.ONet.predict(input_buf)
|
||||
#print(output[2])
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[2][:, 1] > self.threshold[2])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[2][passed, 1].reshape((-1, ))
|
||||
reg = output[1][passed]
|
||||
points = output[0][passed]
|
||||
|
||||
# compute landmark points
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
points[:, 0:5] = np.expand_dims(
|
||||
total_boxes[:, 0], 1) + np.expand_dims(bbw, 1) * points[:, 0:5]
|
||||
points[:, 5:10] = np.expand_dims(
|
||||
total_boxes[:, 1], 1) + np.expand_dims(bbh, 1) * points[:, 5:10]
|
||||
|
||||
# nms
|
||||
total_boxes = self.calibrate_box(total_boxes, reg)
|
||||
pick = nms(total_boxes, 0.7, 'Min')
|
||||
total_boxes = total_boxes[pick]
|
||||
points = points[pick]
|
||||
|
||||
if not self.accurate_landmark:
|
||||
return total_boxes, points
|
||||
|
||||
#############################################
|
||||
# extended stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
patchw = np.maximum(total_boxes[:, 2] - total_boxes[:, 0] + 1,
|
||||
total_boxes[:, 3] - total_boxes[:, 1] + 1)
|
||||
patchw = np.round(patchw * 0.25)
|
||||
|
||||
# make it even
|
||||
patchw[np.where(np.mod(patchw, 2) == 1)] += 1
|
||||
|
||||
input_buf = np.zeros((num_box, 15, 24, 24), dtype=np.float32)
|
||||
for i in range(5):
|
||||
x, y = points[:, i], points[:, i + 5]
|
||||
x, y = np.round(x - 0.5 * patchw), np.round(y - 0.5 * patchw)
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(
|
||||
np.vstack([x, y, x + patchw - 1, y + patchw - 1]).T, width,
|
||||
height)
|
||||
for j in range(num_box):
|
||||
tmpim = np.zeros((tmpw[j], tmpw[j], 3), dtype=np.float32)
|
||||
tmpim[dy[j]:edy[j] + 1,
|
||||
dx[j]:edx[j] + 1, :] = img[y[j]:ey[j] + 1,
|
||||
x[j]:ex[j] + 1, :]
|
||||
input_buf[j, i * 3:i * 3 + 3, :, :] = adjust_input(
|
||||
cv2.resize(tmpim, (24, 24)))
|
||||
|
||||
output = self.LNet.predict(input_buf)
|
||||
|
||||
pointx = np.zeros((num_box, 5))
|
||||
pointy = np.zeros((num_box, 5))
|
||||
|
||||
for k in range(5):
|
||||
# do not make a large movement
|
||||
tmp_index = np.where(np.abs(output[k] - 0.5) > 0.35)
|
||||
output[k][tmp_index[0]] = 0.5
|
||||
|
||||
pointx[:, k] = np.round(points[:, k] -
|
||||
0.5 * patchw) + output[k][:, 0] * patchw
|
||||
pointy[:, k] = np.round(points[:, k + 5] -
|
||||
0.5 * patchw) + output[k][:, 1] * patchw
|
||||
|
||||
points = np.hstack([pointx, pointy])
|
||||
points = points.astype(np.int32)
|
||||
|
||||
return total_boxes, points
|
||||
|
||||
def detect_face(self, img, det_type=0):
|
||||
"""
|
||||
detect face over img
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order of shape (1, 3, n, m)
|
||||
input image
|
||||
Retures:
|
||||
-------
|
||||
bboxes: numpy array, n x 5 (x1,y2,x2,y2,score)
|
||||
bboxes
|
||||
points: numpy array, n x 10 (x1, x2 ... x5, y1, y2 ..y5)
|
||||
landmarks
|
||||
"""
|
||||
|
||||
# check input
|
||||
height, width, _ = img.shape
|
||||
if det_type == 0:
|
||||
MIN_DET_SIZE = 12
|
||||
|
||||
if img is None:
|
||||
return None
|
||||
|
||||
# only works for color image
|
||||
if len(img.shape) != 3:
|
||||
return None
|
||||
|
||||
# detected boxes
|
||||
total_boxes = []
|
||||
|
||||
minl = min(height, width)
|
||||
|
||||
# get all the valid scales
|
||||
scales = []
|
||||
m = MIN_DET_SIZE / self.minsize
|
||||
minl *= m
|
||||
factor_count = 0
|
||||
while minl > MIN_DET_SIZE:
|
||||
scales.append(m * self.factor**factor_count)
|
||||
minl *= self.factor
|
||||
factor_count += 1
|
||||
|
||||
#############################################
|
||||
# first stage
|
||||
#############################################
|
||||
#for scale in scales:
|
||||
# return_boxes = self.detect_first_stage(img, scale, 0)
|
||||
# if return_boxes is not None:
|
||||
# total_boxes.append(return_boxes)
|
||||
|
||||
sliced_index = self.slice_index(len(scales))
|
||||
total_boxes = []
|
||||
for batch in sliced_index:
|
||||
#local_boxes = self.Pool.map( detect_first_stage_warpper, \
|
||||
# izip(repeat(img), self.PNets[:len(batch)], [scales[i] for i in batch], repeat(self.threshold[0])) )
|
||||
local_boxes = map( detect_first_stage_warpper, \
|
||||
izip(repeat(img), self.PNets[:len(batch)], [scales[i] for i in batch], repeat(self.threshold[0])) )
|
||||
total_boxes.extend(local_boxes)
|
||||
|
||||
# remove the Nones
|
||||
total_boxes = [i for i in total_boxes if i is not None]
|
||||
|
||||
if len(total_boxes) == 0:
|
||||
return None
|
||||
|
||||
total_boxes = np.vstack(total_boxes)
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
# merge the detection from first stage
|
||||
pick = nms(total_boxes[:, 0:5], 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
|
||||
# refine the bboxes
|
||||
total_boxes = np.vstack([
|
||||
total_boxes[:, 0] + total_boxes[:, 5] * bbw,
|
||||
total_boxes[:, 1] + total_boxes[:, 6] * bbh,
|
||||
total_boxes[:, 2] + total_boxes[:, 7] * bbw,
|
||||
total_boxes[:, 3] + total_boxes[:, 8] * bbh, total_boxes[:, 4]
|
||||
])
|
||||
|
||||
total_boxes = total_boxes.T
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
else:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
|
||||
#############################################
|
||||
# second stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 24, 24) is the input shape for RNet
|
||||
input_buf = np.zeros((num_box, 3, 24, 24), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (24, 24)))
|
||||
|
||||
output = self.RNet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[1][:, 1] > self.threshold[1])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[1][passed, 1].reshape((-1, ))
|
||||
reg = output[0][passed]
|
||||
|
||||
# nms
|
||||
pick = nms(total_boxes, 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
total_boxes = self.calibrate_box(total_boxes, reg[pick])
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
|
||||
#############################################
|
||||
# third stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 48, 48) is the input shape for ONet
|
||||
input_buf = np.zeros((num_box, 3, 48, 48), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.float32)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (48, 48)))
|
||||
|
||||
output = self.ONet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[2][:, 1] > self.threshold[2])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[2][passed, 1].reshape((-1, ))
|
||||
reg = output[1][passed]
|
||||
points = output[0][passed]
|
||||
|
||||
# compute landmark points
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
points[:, 0:5] = np.expand_dims(
|
||||
total_boxes[:, 0], 1) + np.expand_dims(bbw, 1) * points[:, 0:5]
|
||||
points[:, 5:10] = np.expand_dims(
|
||||
total_boxes[:, 1], 1) + np.expand_dims(bbh, 1) * points[:, 5:10]
|
||||
|
||||
# nms
|
||||
total_boxes = self.calibrate_box(total_boxes, reg)
|
||||
pick = nms(total_boxes, 0.7, 'Min')
|
||||
total_boxes = total_boxes[pick]
|
||||
points = points[pick]
|
||||
|
||||
if not self.accurate_landmark:
|
||||
return total_boxes, points
|
||||
|
||||
#############################################
|
||||
# extended stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
patchw = np.maximum(total_boxes[:, 2] - total_boxes[:, 0] + 1,
|
||||
total_boxes[:, 3] - total_boxes[:, 1] + 1)
|
||||
patchw = np.round(patchw * 0.25)
|
||||
|
||||
# make it even
|
||||
patchw[np.where(np.mod(patchw, 2) == 1)] += 1
|
||||
|
||||
input_buf = np.zeros((num_box, 15, 24, 24), dtype=np.float32)
|
||||
for i in range(5):
|
||||
x, y = points[:, i], points[:, i + 5]
|
||||
x, y = np.round(x - 0.5 * patchw), np.round(y - 0.5 * patchw)
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(
|
||||
np.vstack([x, y, x + patchw - 1, y + patchw - 1]).T, width,
|
||||
height)
|
||||
for j in range(num_box):
|
||||
tmpim = np.zeros((tmpw[j], tmpw[j], 3), dtype=np.float32)
|
||||
tmpim[dy[j]:edy[j] + 1,
|
||||
dx[j]:edx[j] + 1, :] = img[y[j]:ey[j] + 1,
|
||||
x[j]:ex[j] + 1, :]
|
||||
input_buf[j, i * 3:i * 3 + 3, :, :] = adjust_input(
|
||||
cv2.resize(tmpim, (24, 24)))
|
||||
|
||||
output = self.LNet.predict(input_buf)
|
||||
|
||||
pointx = np.zeros((num_box, 5))
|
||||
pointy = np.zeros((num_box, 5))
|
||||
|
||||
for k in range(5):
|
||||
# do not make a large movement
|
||||
tmp_index = np.where(np.abs(output[k] - 0.5) > 0.35)
|
||||
output[k][tmp_index[0]] = 0.5
|
||||
|
||||
pointx[:, k] = np.round(points[:, k] -
|
||||
0.5 * patchw) + output[k][:, 0] * patchw
|
||||
pointy[:, k] = np.round(points[:, k + 5] -
|
||||
0.5 * patchw) + output[k][:, 1] * patchw
|
||||
|
||||
points = np.hstack([pointx, pointy])
|
||||
points = points.astype(np.int32)
|
||||
|
||||
return total_boxes, points
|
||||
|
||||
def list2colmatrix(self, pts_list):
|
||||
"""
|
||||
convert list to column matrix
|
||||
Parameters:
|
||||
----------
|
||||
pts_list:
|
||||
input list
|
||||
Retures:
|
||||
-------
|
||||
colMat:
|
||||
|
||||
"""
|
||||
assert len(pts_list) > 0
|
||||
colMat = []
|
||||
for i in range(len(pts_list)):
|
||||
colMat.append(pts_list[i][0])
|
||||
colMat.append(pts_list[i][1])
|
||||
colMat = np.matrix(colMat).transpose()
|
||||
return colMat
|
||||
|
||||
def find_tfrom_between_shapes(self, from_shape, to_shape):
|
||||
"""
|
||||
find transform between shapes
|
||||
Parameters:
|
||||
----------
|
||||
from_shape:
|
||||
to_shape:
|
||||
Retures:
|
||||
-------
|
||||
tran_m:
|
||||
tran_b:
|
||||
"""
|
||||
assert from_shape.shape[0] == to_shape.shape[
|
||||
0] and from_shape.shape[0] % 2 == 0
|
||||
|
||||
sigma_from = 0.0
|
||||
sigma_to = 0.0
|
||||
cov = np.matrix([[0.0, 0.0], [0.0, 0.0]])
|
||||
|
||||
# compute the mean and cov
|
||||
from_shape_points = from_shape.reshape(from_shape.shape[0] / 2, 2)
|
||||
to_shape_points = to_shape.reshape(to_shape.shape[0] / 2, 2)
|
||||
mean_from = from_shape_points.mean(axis=0)
|
||||
mean_to = to_shape_points.mean(axis=0)
|
||||
|
||||
for i in range(from_shape_points.shape[0]):
|
||||
temp_dis = np.linalg.norm(from_shape_points[i] - mean_from)
|
||||
sigma_from += temp_dis * temp_dis
|
||||
temp_dis = np.linalg.norm(to_shape_points[i] - mean_to)
|
||||
sigma_to += temp_dis * temp_dis
|
||||
cov += (to_shape_points[i].transpose() -
|
||||
mean_to.transpose()) * (from_shape_points[i] - mean_from)
|
||||
|
||||
sigma_from = sigma_from / to_shape_points.shape[0]
|
||||
sigma_to = sigma_to / to_shape_points.shape[0]
|
||||
cov = cov / to_shape_points.shape[0]
|
||||
|
||||
# compute the affine matrix
|
||||
s = np.matrix([[1.0, 0.0], [0.0, 1.0]])
|
||||
u, d, vt = np.linalg.svd(cov)
|
||||
|
||||
if np.linalg.det(cov) < 0:
|
||||
if d[1] < d[0]:
|
||||
s[1, 1] = -1
|
||||
else:
|
||||
s[0, 0] = -1
|
||||
r = u * s * vt
|
||||
c = 1.0
|
||||
if sigma_from != 0:
|
||||
c = 1.0 / sigma_from * np.trace(np.diag(d) * s)
|
||||
|
||||
tran_b = mean_to.transpose() - c * r * mean_from.transpose()
|
||||
tran_m = c * r
|
||||
|
||||
return tran_m, tran_b
|
||||
|
||||
def extract_image_chips(self, img, points, desired_size=256, padding=0):
|
||||
"""
|
||||
crop and align face
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order of shape (1, 3, n, m)
|
||||
input image
|
||||
points: numpy array, n x 10 (x1, x2 ... x5, y1, y2 ..y5)
|
||||
desired_size: default 256
|
||||
padding: default 0
|
||||
Retures:
|
||||
-------
|
||||
crop_imgs: list, n
|
||||
cropped and aligned faces
|
||||
"""
|
||||
crop_imgs = []
|
||||
for p in points:
|
||||
shape = []
|
||||
for k in range(len(p) / 2):
|
||||
shape.append(p[k])
|
||||
shape.append(p[k + 5])
|
||||
|
||||
if padding > 0:
|
||||
padding = padding
|
||||
else:
|
||||
padding = 0
|
||||
# average positions of face points
|
||||
mean_face_shape_x = [
|
||||
0.224152, 0.75610125, 0.490127, 0.254149, 0.726104
|
||||
]
|
||||
mean_face_shape_y = [
|
||||
0.2119465, 0.2119465, 0.628106, 0.780233, 0.780233
|
||||
]
|
||||
|
||||
from_points = []
|
||||
to_points = []
|
||||
|
||||
for i in range(len(shape) / 2):
|
||||
x = (padding + mean_face_shape_x[i]) / (2 * padding +
|
||||
1) * desired_size
|
||||
y = (padding + mean_face_shape_y[i]) / (2 * padding +
|
||||
1) * desired_size
|
||||
to_points.append([x, y])
|
||||
from_points.append([shape[2 * i], shape[2 * i + 1]])
|
||||
|
||||
# convert the points to Mat
|
||||
from_mat = self.list2colmatrix(from_points)
|
||||
to_mat = self.list2colmatrix(to_points)
|
||||
|
||||
# compute the similar transfrom
|
||||
tran_m, tran_b = self.find_tfrom_between_shapes(from_mat, to_mat)
|
||||
|
||||
probe_vec = np.matrix([1.0, 0.0]).transpose()
|
||||
probe_vec = tran_m * probe_vec
|
||||
|
||||
scale = np.linalg.norm(probe_vec)
|
||||
angle = 180.0 / math.pi * math.atan2(probe_vec[1, 0], probe_vec[0,
|
||||
0])
|
||||
|
||||
from_center = [(shape[0] + shape[2]) / 2.0,
|
||||
(shape[1] + shape[3]) / 2.0]
|
||||
to_center = [0, 0]
|
||||
to_center[1] = desired_size * 0.4
|
||||
to_center[0] = desired_size * 0.5
|
||||
|
||||
ex = to_center[0] - from_center[0]
|
||||
ey = to_center[1] - from_center[1]
|
||||
|
||||
rot_mat = cv2.getRotationMatrix2D((from_center[0], from_center[1]),
|
||||
-1 * angle, scale)
|
||||
rot_mat[0][2] += ex
|
||||
rot_mat[1][2] += ey
|
||||
|
||||
chips = cv2.warpAffine(img, rot_mat, (desired_size, desired_size))
|
||||
crop_imgs.append(chips)
|
||||
|
||||
return crop_imgs
|
||||
|
||||
42
detection/README.md
Normal file
42
detection/README.md
Normal file
@@ -0,0 +1,42 @@
|
||||
## Face Detection
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="240"/>
|
||||
</div>
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
These are the face detection methods of [InsightFace](https://insightface.ai)
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/github/11513D05.jpg" width="800"/>
|
||||
</div>
|
||||
|
||||
|
||||
### Datasets
|
||||
|
||||
Please refer to [datasets](_datasets_) page for the details of face detection datasets used for training and evaluation.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Please refer to [evaluation](_evaluation_) page for the details of face recognition evaluation.
|
||||
|
||||
|
||||
## Methods
|
||||
|
||||
|
||||
Supported methods:
|
||||
|
||||
- [x] [RetinaFace (CVPR'2020)](retinaface)
|
||||
- [x] [SCRFD (Arxiv'2021)](scrfd)
|
||||
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
We appreciate all contributions to improve the face detection model zoo of InsightFace.
|
||||
|
||||
|
||||
@@ -4,9 +4,9 @@
|
||||
|
||||
RetinaFace is a practical single-stage [SOTA](http://shuoyang1213.me/WIDERFACE/WiderFace_Results.html) face detector which is initially introduced in [arXiv technical report](https://arxiv.org/abs/1905.00641) and then accepted by [CVPR 2020](https://openaccess.thecvf.com/content_CVPR_2020/html/Deng_RetinaFace_Single-Shot_Multi-Level_Face_Localisation_in_the_Wild_CVPR_2020_paper.html).
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
## Data
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
RetinaFace-Anti-Cov is a customized one stage face detector to help people protect themselves from CovID-19.
|
||||
|
||||

|
||||
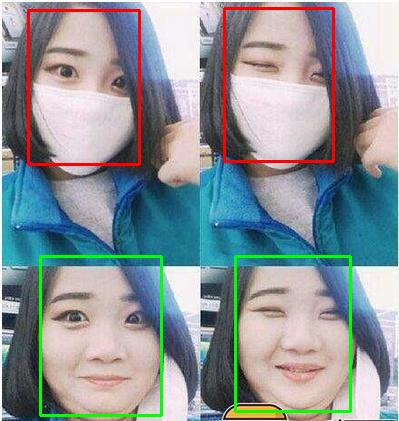
|
||||
|
||||
|
||||
## Testing
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
@@ -1,19 +0,0 @@
|
||||
To reproduce the figures and tables in the notebook, please download everything (model, code, data and meta info) from here:
|
||||
[Dropbox] https://www.dropbox.com/s/33a6haw7v79e5qe/IJB_release.tar?dl=0
|
||||
or
|
||||
[Baidu Cloud] https://pan.baidu.com/s/1oer0p4_mcOrs4cfdeWfbFg
|
||||
|
||||
Please apply for the IJB-B and IJB-C by yourself and strictly follow their distribution licenses.
|
||||
|
||||
Aknowledgement
|
||||
Great thanks for Weidi Xie's instruction [2,3,4,5] to evaluate ArcFace [1] on IJB-B[6] and IJB-C[7].
|
||||
|
||||
[1] Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition[J]. arXiv:1801.07698, 2018.
|
||||
[2] https://github.com/ox-vgg/vgg_face2.
|
||||
[3] Qiong Cao, Li Shen, Weidi Xie, Omkar M Parkhi, Andrew Zisserman. VGGFace2: A dataset for recognising faces across pose and age. FG, 2018.
|
||||
[4] Weidi Xie, Andrew Zisserman. Multicolumn Networks for Face Recognition. BMVC 2018.
|
||||
[5] Weidi Xie, Li Shen, Andrew Zisserman. Comparator Networks. ECCV, 2018.
|
||||
[6] Whitelam, Cameron, Emma Taborsky, Austin Blanton, Brianna Maze, Jocelyn C. Adams, Tim Miller, Nathan D. Kalka et al. IARPA Janus Benchmark-B Face Dataset. CVPR Workshops, 2017.
|
||||
[7] Maze, Brianna, Jocelyn Adams, James A. Duncan, Nathan Kalka, Tim Miller, Charles Otto, Anil K. Jain et al. IARPA Janus Benchmark–C: Face Dataset and Protocol. ICB, 2018.
|
||||
|
||||
|
||||
4
examples/README.md
Normal file
4
examples/README.md
Normal file
@@ -0,0 +1,4 @@
|
||||
InsightFace Example
|
||||
---
|
||||
|
||||
Before running the examples, please install insightface package via `pip install -U insightface`
|
||||
34
examples/demo_analysis.py
Normal file
34
examples/demo_analysis.py
Normal file
@@ -0,0 +1,34 @@
|
||||
import argparse
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import insightface
|
||||
from insightface.app import FaceAnalysis
|
||||
from insightface.data import get_image as ins_get_image
|
||||
|
||||
assert insightface.__version__>='0.3'
|
||||
|
||||
parser = argparse.ArgumentParser(description='insightface app test')
|
||||
# general
|
||||
parser.add_argument('--ctx', default=0, type=int, help='ctx id, <0 means using cpu')
|
||||
parser.add_argument('--det-size', default=640, type=int, help='detection size')
|
||||
args = parser.parse_args()
|
||||
|
||||
app = FaceAnalysis()
|
||||
app.prepare(ctx_id=args.ctx, det_size=(args.det_size,args.det_size))
|
||||
|
||||
img = ins_get_image('t1')
|
||||
faces = app.get(img)
|
||||
assert len(faces)==6
|
||||
rimg = app.draw_on(img, faces)
|
||||
cv2.imwrite("./t1_output.jpg", rimg)
|
||||
|
||||
# then print all-to-all face similarity
|
||||
feats = []
|
||||
for face in faces:
|
||||
feats.append(face.normed_embedding)
|
||||
feats = np.array(feats, dtype=np.float32)
|
||||
sims = np.dot(feats, feats.T)
|
||||
print(sims)
|
||||
|
||||
|
||||
22
examples/mask_renderer.py
Normal file
22
examples/mask_renderer.py
Normal file
@@ -0,0 +1,22 @@
|
||||
import os, sys, datetime
|
||||
import numpy as np
|
||||
import os.path as osp
|
||||
import cv2
|
||||
import insightface
|
||||
from insightface.app import MaskRenderer
|
||||
from insightface.data import get_image as ins_get_image
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
#make sure that you have download correct insightface model pack.
|
||||
#make sure that BFM.mat and BFM_UV.mat have been generated
|
||||
tool = MaskRenderer()
|
||||
tool.prepare(ctx_id=0, det_size=(128,128))
|
||||
image = ins_get_image('Tom_Hanks_54745')
|
||||
mask_image = "mask_blue"
|
||||
params = tool.build_params(image)
|
||||
mask_out = tool.render_mask(image, mask_image, params)
|
||||
|
||||
cv2.imwrite('output_mask.jpg', mask_out)
|
||||
|
||||
|
||||
@@ -2,10 +2,13 @@ import sys
|
||||
import os
|
||||
import argparse
|
||||
import onnx
|
||||
import json
|
||||
import mxnet as mx
|
||||
from onnx import helper
|
||||
from onnx import TensorProto
|
||||
from onnx import numpy_helper
|
||||
import onnxruntime
|
||||
import cv2
|
||||
|
||||
print('mxnet version:', mx.__version__)
|
||||
print('onnx version:', onnx.__version__)
|
||||
@@ -23,12 +26,15 @@ def create_map(graph_member_list):
|
||||
return member_map
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser(description='convert arcface models to onnx')
|
||||
parser = argparse.ArgumentParser(description='convert mxnet model to onnx')
|
||||
# general
|
||||
parser.add_argument('params', default='./r100a/model-0000.params', help='mxnet params to load.')
|
||||
parser.add_argument('output', default='./r100a.onnx', help='path to write onnx model.')
|
||||
parser.add_argument('--eps', default=1.0e-8, type=float, help='eps for weights.')
|
||||
parser.add_argument('--input-shape', default='3,112,112', help='input shape.')
|
||||
parser.add_argument('--check', action='store_true')
|
||||
parser.add_argument('--input-mean', default=0.0, type=float, help='input mean for checking.')
|
||||
parser.add_argument('--input-std', default=1.0, type=float, help='input std for checking.')
|
||||
args = parser.parse_args()
|
||||
input_shape = (1,) + tuple( [int(x) for x in args.input_shape.split(',')] )
|
||||
|
||||
@@ -41,6 +47,29 @@ assert os.path.exists(sym_file)
|
||||
assert os.path.exists(params_file)
|
||||
|
||||
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
|
||||
|
||||
nodes = json.loads(sym.tojson())['nodes']
|
||||
bn_fixgamma_list = []
|
||||
for nodeid, node in enumerate(nodes):
|
||||
if node['op'] == 'BatchNorm':
|
||||
attr = node['attrs']
|
||||
fix_gamma = False
|
||||
if attr is not None and 'fix_gamma' in attr:
|
||||
if str(attr['fix_gamma']).lower()=='true':
|
||||
fix_gamma = True
|
||||
if fix_gamma:
|
||||
bn_fixgamma_list.append(node['name'])
|
||||
#print(node, fix_gamma)
|
||||
|
||||
print('fixgamma list:', bn_fixgamma_list)
|
||||
layer = None
|
||||
#layer = 'conv_2_dw_relu' #for debug
|
||||
|
||||
if layer is not None:
|
||||
all_layers = sym.get_internals()
|
||||
sym = all_layers[layer + '_output']
|
||||
|
||||
|
||||
eps = args.eps
|
||||
|
||||
arg = {}
|
||||
@@ -50,24 +79,27 @@ ac = 0
|
||||
for k in arg_params:
|
||||
v = arg_params[k]
|
||||
nv = v.asnumpy()
|
||||
#print(k, nv.dtype)
|
||||
nv = nv.astype(np.float32)
|
||||
#print(k, nv.shape)
|
||||
if k.endswith('_gamma'):
|
||||
bnname = k[:-6]
|
||||
if bnname in bn_fixgamma_list:
|
||||
nv[:] = 1.0
|
||||
ac += nv.size
|
||||
invalid += np.count_nonzero(np.abs(nv)<eps)
|
||||
nv[np.abs(nv) < eps] = 0.0
|
||||
arg[k] = mx.nd.array(nv, dtype='float32')
|
||||
print(invalid, ac)
|
||||
arg_params = arg
|
||||
invalid = 0
|
||||
ac = 0
|
||||
for k in aux_params:
|
||||
v = aux_params[k]
|
||||
nv = v.asnumpy().astype(np.float32)
|
||||
|
||||
ac += nv.size
|
||||
invalid += np.count_nonzero(np.abs(nv)<eps)
|
||||
nv[np.abs(nv) < eps] = 0.0
|
||||
aux[k] = mx.nd.array(nv, dtype='float32')
|
||||
print(invalid, ac)
|
||||
aux_params = aux
|
||||
|
||||
all_args = {}
|
||||
@@ -75,6 +107,7 @@ all_args.update(arg_params)
|
||||
all_args.update(aux_params)
|
||||
converted_model_path = onnx_mxnet.export_model(sym, all_args, [input_shape], np.float32, args.output, opset_version=11)
|
||||
|
||||
|
||||
model = onnx.load(args.output)
|
||||
graph = model.graph
|
||||
input_map = create_map(graph.input)
|
||||
@@ -90,8 +123,8 @@ for input_name in input_map.keys():
|
||||
node = node_map[node_name]
|
||||
if node.op_type!='PRelu':
|
||||
continue
|
||||
input_shape = input_map[input_name].type.tensor_type.shape.dim
|
||||
input_dim_val=input_shape[0].dim_value
|
||||
_input_shape = input_map[input_name].type.tensor_type.shape.dim
|
||||
input_dim_val=_input_shape[0].dim_value
|
||||
|
||||
graph.initializer.remove(init_map[input_name])
|
||||
weight_array = numpy_helper.to_array(init_map[input_name])
|
||||
@@ -113,3 +146,31 @@ graph.input[0].type.tensor_type.shape.dim[0].dim_param = 'None'
|
||||
|
||||
onnx.save(model, args.output)
|
||||
|
||||
#start to check correctness
|
||||
if args.check:
|
||||
im_size = tuple(input_shape[2:])+(3,)
|
||||
img = np.random.randint(0, 256, size=im_size, dtype=np.uint8)
|
||||
input_size = tuple(input_shape[2:4][::-1])
|
||||
input_std = args.input_std
|
||||
input_mean = args.input_mean
|
||||
#print(img.shape, input_size)
|
||||
img = cv2.dnn.blobFromImage(img, 1.0/input_std, input_size, (input_mean, input_mean, input_mean), swapRB=True)
|
||||
ctx = mx.cpu()
|
||||
model = mx.mod.Module(symbol=sym, context=ctx, label_names = None)
|
||||
model.bind(for_training=False, data_shapes=[('data', input_shape)])
|
||||
_, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch) #reload original params
|
||||
model.set_params(arg_params, aux_params)
|
||||
|
||||
data = mx.nd.array(img)
|
||||
db = mx.io.DataBatch(data=(data,))
|
||||
model.forward(db, is_train=False)
|
||||
x1 = model.get_outputs()[-1].asnumpy()
|
||||
|
||||
session = onnxruntime.InferenceSession(args.output, None)
|
||||
input_name = session.get_inputs()[0].name
|
||||
output_name = session.get_outputs()[0].name
|
||||
x2 = session.run([output_name], {input_name : img})[0]
|
||||
print(x1.shape, x2.shape)
|
||||
print(x1.flatten()[:20])
|
||||
print(x2.flatten()[:20])
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 12 KiB |
@@ -1,281 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import random
|
||||
import logging
|
||||
import sys
|
||||
import numbers
|
||||
import math
|
||||
import sklearn
|
||||
import datetime
|
||||
import numpy as np
|
||||
import cv2
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
import mxnet as mx
|
||||
from mxnet import ndarray as nd
|
||||
from mxnet import io
|
||||
from mxnet import recordio
|
||||
|
||||
logger = logging.getLogger()
|
||||
|
||||
|
||||
class FaceImageIter(io.DataIter):
|
||||
def __init__(self,
|
||||
batch_size,
|
||||
data_shape,
|
||||
path_imgrec=None,
|
||||
shuffle=False,
|
||||
aug_list=None,
|
||||
mean=None,
|
||||
rand_mirror=False,
|
||||
cutoff=0,
|
||||
color_jittering=0,
|
||||
data_name='data',
|
||||
label_name='softmax_label',
|
||||
**kwargs):
|
||||
super(FaceImageIter, self).__init__()
|
||||
assert path_imgrec
|
||||
logging.info('loading recordio %s...', path_imgrec)
|
||||
path_imgidx = path_imgrec[0:-4] + ".idx"
|
||||
self.imgrec = recordio.MXIndexedRecordIO(path_imgidx, path_imgrec, 'r') # pylint: disable=redefined-variable-type
|
||||
s = self.imgrec.read_idx(0)
|
||||
header, _ = recordio.unpack(s)
|
||||
self.imgidx = list(self.imgrec.keys)
|
||||
self.seq = self.imgidx
|
||||
|
||||
self.mean = mean
|
||||
self.nd_mean = None
|
||||
if self.mean:
|
||||
self.mean = np.array(self.mean, dtype=np.float32).reshape(1, 1, 3)
|
||||
self.nd_mean = mx.nd.array(self.mean).reshape((1, 1, 3))
|
||||
|
||||
self.check_data_shape(data_shape)
|
||||
self.provide_data = [(data_name, (batch_size, ) + data_shape)]
|
||||
self.batch_size = batch_size
|
||||
self.data_shape = data_shape
|
||||
self.shuffle = shuffle
|
||||
self.image_size = '%d,%d' % (data_shape[1], data_shape[2])
|
||||
self.rand_mirror = rand_mirror
|
||||
print('rand_mirror', rand_mirror)
|
||||
self.cutoff = cutoff
|
||||
self.color_jittering = color_jittering
|
||||
self.CJA = mx.image.ColorJitterAug(0.125, 0.125, 0.125)
|
||||
self.provide_label = [(label_name, (batch_size, 101))]
|
||||
#print(self.provide_label[0][1])
|
||||
self.cur = 0
|
||||
self.nbatch = 0
|
||||
self.is_init = False
|
||||
|
||||
def reset(self):
|
||||
"""Resets the iterator to the beginning of the data."""
|
||||
print('call reset()')
|
||||
self.cur = 0
|
||||
if self.shuffle:
|
||||
random.shuffle(self.seq)
|
||||
if self.seq is None and self.imgrec is not None:
|
||||
self.imgrec.reset()
|
||||
|
||||
def num_samples(self):
|
||||
return len(self.seq)
|
||||
|
||||
def next_sample(self):
|
||||
if self.cur >= len(self.seq):
|
||||
raise StopIteration
|
||||
idx = self.seq[self.cur]
|
||||
self.cur += 1
|
||||
s = self.imgrec.read_idx(idx)
|
||||
header, img = recordio.unpack(s)
|
||||
label = header.label
|
||||
return label, img, None, None
|
||||
|
||||
def brightness_aug(self, src, x):
|
||||
alpha = 1.0 + random.uniform(-x, x)
|
||||
src *= alpha
|
||||
return src
|
||||
|
||||
def contrast_aug(self, src, x):
|
||||
alpha = 1.0 + random.uniform(-x, x)
|
||||
coef = nd.array([[[0.299, 0.587, 0.114]]])
|
||||
gray = src * coef
|
||||
gray = (3.0 * (1.0 - alpha) / gray.size) * nd.sum(gray)
|
||||
src *= alpha
|
||||
src += gray
|
||||
return src
|
||||
|
||||
def saturation_aug(self, src, x):
|
||||
alpha = 1.0 + random.uniform(-x, x)
|
||||
coef = nd.array([[[0.299, 0.587, 0.114]]])
|
||||
gray = src * coef
|
||||
gray = nd.sum(gray, axis=2, keepdims=True)
|
||||
gray *= (1.0 - alpha)
|
||||
src *= alpha
|
||||
src += gray
|
||||
return src
|
||||
|
||||
def color_aug(self, img, x):
|
||||
#augs = [self.brightness_aug, self.contrast_aug, self.saturation_aug]
|
||||
#random.shuffle(augs)
|
||||
#for aug in augs:
|
||||
# #print(img.shape)
|
||||
# img = aug(img, x)
|
||||
# #print(img.shape)
|
||||
#return img
|
||||
return self.CJA(img)
|
||||
|
||||
def mirror_aug(self, img):
|
||||
_rd = random.randint(0, 1)
|
||||
if _rd == 1:
|
||||
for c in range(img.shape[2]):
|
||||
img[:, :, c] = np.fliplr(img[:, :, c])
|
||||
return img
|
||||
|
||||
def compress_aug(self, img):
|
||||
buf = BytesIO()
|
||||
img = Image.fromarray(img.asnumpy(), 'RGB')
|
||||
q = random.randint(2, 20)
|
||||
img.save(buf, format='JPEG', quality=q)
|
||||
buf = buf.getvalue()
|
||||
img = Image.open(BytesIO(buf))
|
||||
return nd.array(np.asarray(img, 'float32'))
|
||||
|
||||
def next(self):
|
||||
if not self.is_init:
|
||||
self.reset()
|
||||
self.is_init = True
|
||||
"""Returns the next batch of data."""
|
||||
#print('in next', self.cur, self.labelcur)
|
||||
self.nbatch += 1
|
||||
batch_size = self.batch_size
|
||||
c, h, w = self.data_shape
|
||||
batch_data = nd.empty((batch_size, c, h, w))
|
||||
if self.provide_label is not None:
|
||||
batch_label = nd.empty(self.provide_label[0][1])
|
||||
i = 0
|
||||
try:
|
||||
while i < batch_size:
|
||||
#print('XXXX', i)
|
||||
label, s, bbox, landmark = self.next_sample()
|
||||
gender = int(label[0])
|
||||
age = int(label[1])
|
||||
assert age >= 0
|
||||
#assert gender==0 or gender==1
|
||||
plabel = np.zeros(shape=(101, ), dtype=np.float32)
|
||||
plabel[0] = gender
|
||||
if age == 0:
|
||||
age = 1
|
||||
if age > 100:
|
||||
age = 100
|
||||
plabel[1:age + 1] = 1
|
||||
label = plabel
|
||||
_data = self.imdecode(s)
|
||||
if _data.shape[0] != self.data_shape[1]:
|
||||
_data = mx.image.resize_short(_data, self.data_shape[1])
|
||||
if self.rand_mirror:
|
||||
_rd = random.randint(0, 1)
|
||||
if _rd == 1:
|
||||
_data = mx.ndarray.flip(data=_data, axis=1)
|
||||
if self.color_jittering > 0:
|
||||
if self.color_jittering > 1:
|
||||
_rd = random.randint(0, 1)
|
||||
if _rd == 1:
|
||||
_data = self.compress_aug(_data)
|
||||
#print('do color aug')
|
||||
_data = _data.astype('float32', copy=False)
|
||||
#print(_data.__class__)
|
||||
_data = self.color_aug(_data, 0.125)
|
||||
if self.nd_mean is not None:
|
||||
_data = _data.astype('float32', copy=False)
|
||||
_data -= self.nd_mean
|
||||
_data *= 0.0078125
|
||||
if self.cutoff > 0:
|
||||
_rd = random.randint(0, 1)
|
||||
if _rd == 1:
|
||||
#print('do cutoff aug', self.cutoff)
|
||||
centerh = random.randint(0, _data.shape[0] - 1)
|
||||
centerw = random.randint(0, _data.shape[1] - 1)
|
||||
half = self.cutoff // 2
|
||||
starth = max(0, centerh - half)
|
||||
endh = min(_data.shape[0], centerh + half)
|
||||
startw = max(0, centerw - half)
|
||||
endw = min(_data.shape[1], centerw + half)
|
||||
#print(starth, endh, startw, endw, _data.shape)
|
||||
_data[starth:endh, startw:endw, :] = 128
|
||||
data = [_data]
|
||||
for datum in data:
|
||||
assert i < batch_size, 'Batch size must be multiples of augmenter output length'
|
||||
#print(datum.shape)
|
||||
batch_data[i][:] = self.postprocess_data(datum)
|
||||
batch_label[i][:] = label
|
||||
i += 1
|
||||
except StopIteration:
|
||||
if i < batch_size:
|
||||
raise StopIteration
|
||||
|
||||
return io.DataBatch([batch_data], [batch_label], batch_size - i)
|
||||
|
||||
def check_data_shape(self, data_shape):
|
||||
"""Checks if the input data shape is valid"""
|
||||
if not len(data_shape) == 3:
|
||||
raise ValueError(
|
||||
'data_shape should have length 3, with dimensions CxHxW')
|
||||
if not data_shape[0] == 3:
|
||||
raise ValueError(
|
||||
'This iterator expects inputs to have 3 channels.')
|
||||
|
||||
def check_valid_image(self, data):
|
||||
"""Checks if the input data is valid"""
|
||||
if len(data[0].shape) == 0:
|
||||
raise RuntimeError('Data shape is wrong')
|
||||
|
||||
def imdecode(self, s):
|
||||
"""Decodes a string or byte string to an NDArray.
|
||||
See mx.img.imdecode for more details."""
|
||||
img = mx.image.imdecode(s) #mx.ndarray
|
||||
return img
|
||||
|
||||
def read_image(self, fname):
|
||||
"""Reads an input image `fname` and returns the decoded raw bytes.
|
||||
|
||||
Example usage:
|
||||
----------
|
||||
>>> dataIter.read_image('Face.jpg') # returns decoded raw bytes.
|
||||
"""
|
||||
with open(os.path.join(self.path_root, fname), 'rb') as fin:
|
||||
img = fin.read()
|
||||
return img
|
||||
|
||||
def augmentation_transform(self, data):
|
||||
"""Transforms input data with specified augmentation."""
|
||||
for aug in self.auglist:
|
||||
data = [ret for src in data for ret in aug(src)]
|
||||
return data
|
||||
|
||||
def postprocess_data(self, datum):
|
||||
"""Final postprocessing step before image is loaded into the batch."""
|
||||
return nd.transpose(datum, axes=(2, 0, 1))
|
||||
|
||||
|
||||
class FaceImageIterList(io.DataIter):
|
||||
def __init__(self, iter_list):
|
||||
assert len(iter_list) > 0
|
||||
self.provide_data = iter_list[0].provide_data
|
||||
self.provide_label = iter_list[0].provide_label
|
||||
self.iter_list = iter_list
|
||||
self.cur_iter = None
|
||||
|
||||
def reset(self):
|
||||
self.cur_iter.reset()
|
||||
|
||||
def next(self):
|
||||
self.cur_iter = random.choice(self.iter_list)
|
||||
while True:
|
||||
try:
|
||||
ret = self.cur_iter.next()
|
||||
except StopIteration:
|
||||
self.cur_iter.reset()
|
||||
continue
|
||||
return ret
|
||||
@@ -1,109 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
from scipy import misc
|
||||
import sys
|
||||
import os
|
||||
import argparse
|
||||
#import tensorflow as tf
|
||||
import numpy as np
|
||||
import mxnet as mx
|
||||
import random
|
||||
import cv2
|
||||
import sklearn
|
||||
from sklearn.decomposition import PCA
|
||||
from time import sleep
|
||||
from easydict import EasyDict as edict
|
||||
from mtcnn_detector import MtcnnDetector
|
||||
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'src', 'common'))
|
||||
import face_image
|
||||
import face_preprocess
|
||||
|
||||
|
||||
def do_flip(data):
|
||||
for idx in range(data.shape[0]):
|
||||
data[idx, :, :] = np.fliplr(data[idx, :, :])
|
||||
|
||||
|
||||
def get_model(ctx, image_size, model_str, layer):
|
||||
_vec = model_str.split(',')
|
||||
assert len(_vec) == 2
|
||||
prefix = _vec[0]
|
||||
epoch = int(_vec[1])
|
||||
print('loading', prefix, epoch)
|
||||
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
|
||||
all_layers = sym.get_internals()
|
||||
sym = all_layers[layer + '_output']
|
||||
model = mx.mod.Module(symbol=sym, context=ctx, label_names=None)
|
||||
#model.bind(data_shapes=[('data', (args.batch_size, 3, image_size[0], image_size[1]))], label_shapes=[('softmax_label', (args.batch_size,))])
|
||||
model.bind(data_shapes=[('data', (1, 3, image_size[0], image_size[1]))])
|
||||
model.set_params(arg_params, aux_params)
|
||||
return model
|
||||
|
||||
|
||||
class FaceModel:
|
||||
def __init__(self, args):
|
||||
self.args = args
|
||||
if args.gpu >= 0:
|
||||
ctx = mx.gpu(args.gpu)
|
||||
else:
|
||||
ctx = mx.cpu()
|
||||
_vec = args.image_size.split(',')
|
||||
assert len(_vec) == 2
|
||||
image_size = (int(_vec[0]), int(_vec[1]))
|
||||
self.model = None
|
||||
if len(args.model) > 0:
|
||||
self.model = get_model(ctx, image_size, args.model, 'fc1')
|
||||
|
||||
self.det_minsize = 50
|
||||
self.det_threshold = [0.6, 0.7, 0.8]
|
||||
#self.det_factor = 0.9
|
||||
self.image_size = image_size
|
||||
mtcnn_path = os.path.join(os.path.dirname(__file__), 'mtcnn-model')
|
||||
if args.det == 0:
|
||||
detector = MtcnnDetector(model_folder=mtcnn_path,
|
||||
ctx=ctx,
|
||||
num_worker=1,
|
||||
accurate_landmark=True,
|
||||
threshold=self.det_threshold)
|
||||
else:
|
||||
detector = MtcnnDetector(model_folder=mtcnn_path,
|
||||
ctx=ctx,
|
||||
num_worker=1,
|
||||
accurate_landmark=True,
|
||||
threshold=[0.0, 0.0, 0.2])
|
||||
self.detector = detector
|
||||
|
||||
def get_input(self, face_img):
|
||||
ret = self.detector.detect_face(face_img, det_type=self.args.det)
|
||||
if ret is None:
|
||||
return None
|
||||
bbox, points = ret
|
||||
if bbox.shape[0] == 0:
|
||||
return None
|
||||
bbox = bbox[0, 0:4]
|
||||
points = points[0, :].reshape((2, 5)).T
|
||||
#print(bbox)
|
||||
#print(points)
|
||||
nimg = face_preprocess.preprocess(face_img,
|
||||
bbox,
|
||||
points,
|
||||
image_size='112,112')
|
||||
nimg = cv2.cvtColor(nimg, cv2.COLOR_BGR2RGB)
|
||||
aligned = np.transpose(nimg, (2, 0, 1))
|
||||
input_blob = np.expand_dims(aligned, axis=0)
|
||||
data = mx.nd.array(input_blob)
|
||||
db = mx.io.DataBatch(data=(data, ))
|
||||
return db
|
||||
|
||||
def get_ga(self, data):
|
||||
self.model.forward(data, is_train=False)
|
||||
ret = self.model.get_outputs()[0].asnumpy()
|
||||
g = ret[:, 0:2].flatten()
|
||||
gender = np.argmax(g)
|
||||
a = ret[:, 2:202].reshape((100, 2))
|
||||
a = np.argmax(a, axis=1)
|
||||
age = int(sum(a))
|
||||
|
||||
return gender, age
|
||||
@@ -1,172 +0,0 @@
|
||||
# coding: utf-8
|
||||
# YuanYang
|
||||
import math
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
|
||||
def nms(boxes, overlap_threshold, mode='Union'):
|
||||
"""
|
||||
non max suppression
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
box: numpy array n x 5
|
||||
input bbox array
|
||||
overlap_threshold: float number
|
||||
threshold of overlap
|
||||
mode: float number
|
||||
how to compute overlap ratio, 'Union' or 'Min'
|
||||
Returns:
|
||||
-------
|
||||
index array of the selected bbox
|
||||
"""
|
||||
# if there are no boxes, return an empty list
|
||||
if len(boxes) == 0:
|
||||
return []
|
||||
|
||||
# if the bounding boxes integers, convert them to floats
|
||||
if boxes.dtype.kind == "i":
|
||||
boxes = boxes.astype("float")
|
||||
|
||||
# initialize the list of picked indexes
|
||||
pick = []
|
||||
|
||||
# grab the coordinates of the bounding boxes
|
||||
x1, y1, x2, y2, score = [boxes[:, i] for i in range(5)]
|
||||
|
||||
area = (x2 - x1 + 1) * (y2 - y1 + 1)
|
||||
idxs = np.argsort(score)
|
||||
|
||||
# keep looping while some indexes still remain in the indexes list
|
||||
while len(idxs) > 0:
|
||||
# grab the last index in the indexes list and add the index value to the list of picked indexes
|
||||
last = len(idxs) - 1
|
||||
i = idxs[last]
|
||||
pick.append(i)
|
||||
|
||||
xx1 = np.maximum(x1[i], x1[idxs[:last]])
|
||||
yy1 = np.maximum(y1[i], y1[idxs[:last]])
|
||||
xx2 = np.minimum(x2[i], x2[idxs[:last]])
|
||||
yy2 = np.minimum(y2[i], y2[idxs[:last]])
|
||||
|
||||
# compute the width and height of the bounding box
|
||||
w = np.maximum(0, xx2 - xx1 + 1)
|
||||
h = np.maximum(0, yy2 - yy1 + 1)
|
||||
|
||||
inter = w * h
|
||||
if mode == 'Min':
|
||||
overlap = inter / np.minimum(area[i], area[idxs[:last]])
|
||||
else:
|
||||
overlap = inter / (area[i] + area[idxs[:last]] - inter)
|
||||
|
||||
# delete all indexes from the index list that have
|
||||
idxs = np.delete(
|
||||
idxs,
|
||||
np.concatenate(([last], np.where(overlap > overlap_threshold)[0])))
|
||||
|
||||
return pick
|
||||
|
||||
|
||||
def adjust_input(in_data):
|
||||
"""
|
||||
adjust the input from (h, w, c) to ( 1, c, h, w) for network input
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
in_data: numpy array of shape (h, w, c)
|
||||
input data
|
||||
Returns:
|
||||
-------
|
||||
out_data: numpy array of shape (1, c, h, w)
|
||||
reshaped array
|
||||
"""
|
||||
if in_data.dtype is not np.dtype('float32'):
|
||||
out_data = in_data.astype(np.float32)
|
||||
else:
|
||||
out_data = in_data
|
||||
|
||||
out_data = out_data.transpose((2, 0, 1))
|
||||
out_data = np.expand_dims(out_data, 0)
|
||||
out_data = (out_data - 127.5) * 0.0078125
|
||||
return out_data
|
||||
|
||||
|
||||
def generate_bbox(map, reg, scale, threshold):
|
||||
"""
|
||||
generate bbox from feature map
|
||||
Parameters:
|
||||
----------
|
||||
map: numpy array , n x m x 1
|
||||
detect score for each position
|
||||
reg: numpy array , n x m x 4
|
||||
bbox
|
||||
scale: float number
|
||||
scale of this detection
|
||||
threshold: float number
|
||||
detect threshold
|
||||
Returns:
|
||||
-------
|
||||
bbox array
|
||||
"""
|
||||
stride = 2
|
||||
cellsize = 12
|
||||
|
||||
t_index = np.where(map > threshold)
|
||||
|
||||
# find nothing
|
||||
if t_index[0].size == 0:
|
||||
return np.array([])
|
||||
|
||||
dx1, dy1, dx2, dy2 = [reg[0, i, t_index[0], t_index[1]] for i in range(4)]
|
||||
|
||||
reg = np.array([dx1, dy1, dx2, dy2])
|
||||
score = map[t_index[0], t_index[1]]
|
||||
boundingbox = np.vstack([
|
||||
np.round((stride * t_index[1] + 1) / scale),
|
||||
np.round((stride * t_index[0] + 1) / scale),
|
||||
np.round((stride * t_index[1] + 1 + cellsize) / scale),
|
||||
np.round((stride * t_index[0] + 1 + cellsize) / scale), score, reg
|
||||
])
|
||||
|
||||
return boundingbox.T
|
||||
|
||||
|
||||
def detect_first_stage(img, net, scale, threshold):
|
||||
"""
|
||||
run PNet for first stage
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order
|
||||
input image
|
||||
scale: float number
|
||||
how much should the input image scale
|
||||
net: PNet
|
||||
worker
|
||||
Returns:
|
||||
-------
|
||||
total_boxes : bboxes
|
||||
"""
|
||||
height, width, _ = img.shape
|
||||
hs = int(math.ceil(height * scale))
|
||||
ws = int(math.ceil(width * scale))
|
||||
|
||||
im_data = cv2.resize(img, (ws, hs))
|
||||
|
||||
# adjust for the network input
|
||||
input_buf = adjust_input(im_data)
|
||||
output = net.predict(input_buf)
|
||||
boxes = generate_bbox(output[1][0, 1, :, :], output[0], scale, threshold)
|
||||
|
||||
if boxes.size == 0:
|
||||
return None
|
||||
|
||||
# nms
|
||||
pick = nms(boxes[:, 0:5], 0.5, mode='Union')
|
||||
boxes = boxes[pick]
|
||||
return boxes
|
||||
|
||||
|
||||
def detect_first_stage_warpper(args):
|
||||
return detect_first_stage(*args)
|
||||
Binary file not shown.
File diff suppressed because it is too large
Load Diff
Binary file not shown.
@@ -1,266 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "10",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(2,2)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "16",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "32",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[11, 0], [12, 0], [13, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[14, 0], [15, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(1,1)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "4",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4_2",
|
||||
"inputs": [[16, 0], [17, 0], [18, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(1,1)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "2",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4_1",
|
||||
"inputs": [[16, 0], [20, 0], [21, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxActivation",
|
||||
"param": {"mode": "channel"},
|
||||
"name": "prob1",
|
||||
"inputs": [[22, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
12,
|
||||
13,
|
||||
15,
|
||||
17,
|
||||
18,
|
||||
20,
|
||||
21
|
||||
],
|
||||
"heads": [[19, 0], [23, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,177 +0,0 @@
|
||||
name: "PNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 12
|
||||
input_dim: 12
|
||||
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 10
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 2
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 16
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "conv2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 32
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "PReLU3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv4-1"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4-1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 2
|
||||
kernel_size: 1
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv4-2"
|
||||
type: "Convolution"
|
||||
bottom: "conv3"
|
||||
top: "conv4-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 4
|
||||
kernel_size: 1
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv4-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
@@ -1,324 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "28",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "48",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool2",
|
||||
"inputs": [[11, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(2,2)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[12, 0], [13, 0], [14, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[15, 0], [16, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "128"
|
||||
},
|
||||
"name": "conv4",
|
||||
"inputs": [[17, 0], [18, 0], [19, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu4_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu4",
|
||||
"inputs": [[20, 0], [21, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "4"
|
||||
},
|
||||
"name": "conv5_2",
|
||||
"inputs": [[22, 0], [23, 0], [24, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "2"
|
||||
},
|
||||
"name": "conv5_1",
|
||||
"inputs": [[22, 0], [26, 0], [27, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prob1_label",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxOutput",
|
||||
"param": {
|
||||
"grad_scale": "1",
|
||||
"ignore_label": "-1",
|
||||
"multi_output": "False",
|
||||
"normalization": "null",
|
||||
"use_ignore": "False"
|
||||
},
|
||||
"name": "prob1",
|
||||
"inputs": [[28, 0], [29, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
13,
|
||||
14,
|
||||
16,
|
||||
18,
|
||||
19,
|
||||
21,
|
||||
23,
|
||||
24,
|
||||
26,
|
||||
27,
|
||||
29
|
||||
],
|
||||
"heads": [[25, 0], [30, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,228 +0,0 @@
|
||||
name: "RNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 24
|
||||
input_dim: 24
|
||||
|
||||
|
||||
##########################
|
||||
######################
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
propagate_down: true
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
propagate_down: true
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
####################################
|
||||
|
||||
##################################
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
propagate_down: true
|
||||
}
|
||||
###############################
|
||||
|
||||
###############################
|
||||
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 128
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv5-1"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5-1"
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
param {
|
||||
lr_mult: 0
|
||||
decay_mult: 0
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
#kernel_size: 1
|
||||
#stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv5-2"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 4
|
||||
#kernel_size: 1
|
||||
#stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv5-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
@@ -1,418 +0,0 @@
|
||||
{
|
||||
"nodes": [
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "data",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "32",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv1",
|
||||
"inputs": [[0, 0], [1, 0], [2, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu1_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu1",
|
||||
"inputs": [[3, 0], [4, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool1",
|
||||
"inputs": [[5, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv2",
|
||||
"inputs": [[6, 0], [7, 0], [8, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu2_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu2",
|
||||
"inputs": [[9, 0], [10, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(3,3)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool2",
|
||||
"inputs": [[11, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(3,3)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "64",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv3",
|
||||
"inputs": [[12, 0], [13, 0], [14, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu3_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu3",
|
||||
"inputs": [[15, 0], [16, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Pooling",
|
||||
"param": {
|
||||
"global_pool": "False",
|
||||
"kernel": "(2,2)",
|
||||
"pad": "(0,0)",
|
||||
"pool_type": "max",
|
||||
"pooling_convention": "full",
|
||||
"stride": "(2,2)"
|
||||
},
|
||||
"name": "pool3",
|
||||
"inputs": [[17, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv4_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "Convolution",
|
||||
"param": {
|
||||
"cudnn_off": "False",
|
||||
"cudnn_tune": "off",
|
||||
"dilate": "(1,1)",
|
||||
"kernel": "(2,2)",
|
||||
"no_bias": "False",
|
||||
"num_filter": "128",
|
||||
"num_group": "1",
|
||||
"pad": "(0,0)",
|
||||
"stride": "(1,1)",
|
||||
"workspace": "1024"
|
||||
},
|
||||
"name": "conv4",
|
||||
"inputs": [[18, 0], [19, 0], [20, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu4_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu4",
|
||||
"inputs": [[21, 0], [22, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv5_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "256"
|
||||
},
|
||||
"name": "conv5",
|
||||
"inputs": [[23, 0], [24, 0], [25, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prelu5_gamma",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "LeakyReLU",
|
||||
"param": {
|
||||
"act_type": "prelu",
|
||||
"lower_bound": "0.125",
|
||||
"slope": "0.25",
|
||||
"upper_bound": "0.334"
|
||||
},
|
||||
"name": "prelu5",
|
||||
"inputs": [[26, 0], [27, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_3_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_3_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "10"
|
||||
},
|
||||
"name": "conv6_3",
|
||||
"inputs": [[28, 0], [29, 0], [30, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_2_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_2_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "4"
|
||||
},
|
||||
"name": "conv6_2",
|
||||
"inputs": [[28, 0], [32, 0], [33, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_1_weight",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "conv6_1_bias",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "FullyConnected",
|
||||
"param": {
|
||||
"no_bias": "False",
|
||||
"num_hidden": "2"
|
||||
},
|
||||
"name": "conv6_1",
|
||||
"inputs": [[28, 0], [35, 0], [36, 0]],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "null",
|
||||
"param": {},
|
||||
"name": "prob1_label",
|
||||
"inputs": [],
|
||||
"backward_source_id": -1
|
||||
},
|
||||
{
|
||||
"op": "SoftmaxOutput",
|
||||
"param": {
|
||||
"grad_scale": "1",
|
||||
"ignore_label": "-1",
|
||||
"multi_output": "False",
|
||||
"normalization": "null",
|
||||
"use_ignore": "False"
|
||||
},
|
||||
"name": "prob1",
|
||||
"inputs": [[37, 0], [38, 0]],
|
||||
"backward_source_id": -1
|
||||
}
|
||||
],
|
||||
"arg_nodes": [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
4,
|
||||
7,
|
||||
8,
|
||||
10,
|
||||
13,
|
||||
14,
|
||||
16,
|
||||
19,
|
||||
20,
|
||||
22,
|
||||
24,
|
||||
25,
|
||||
27,
|
||||
29,
|
||||
30,
|
||||
32,
|
||||
33,
|
||||
35,
|
||||
36,
|
||||
38
|
||||
],
|
||||
"heads": [[31, 0], [34, 0], [39, 0]]
|
||||
}
|
||||
Binary file not shown.
@@ -1,294 +0,0 @@
|
||||
name: "ONet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 3
|
||||
input_dim: 48
|
||||
input_dim: 48
|
||||
##################################
|
||||
layer {
|
||||
name: "conv1"
|
||||
type: "Convolution"
|
||||
bottom: "data"
|
||||
top: "conv1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 32
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1"
|
||||
top: "conv1"
|
||||
}
|
||||
layer {
|
||||
name: "pool1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1"
|
||||
top: "pool1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1"
|
||||
top: "conv2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "prelu2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2"
|
||||
top: "conv2"
|
||||
}
|
||||
layer {
|
||||
name: "pool2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2"
|
||||
top: "pool2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2"
|
||||
top: "conv3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 3
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3"
|
||||
top: "conv3"
|
||||
}
|
||||
layer {
|
||||
name: "pool3"
|
||||
type: "Pooling"
|
||||
bottom: "conv3"
|
||||
top: "pool3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 2
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv4"
|
||||
type: "Convolution"
|
||||
bottom: "pool3"
|
||||
top: "conv4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 128
|
||||
kernel_size: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "conv4"
|
||||
top: "conv4"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv5"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv4"
|
||||
top: "conv5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 3
|
||||
num_output: 256
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "drop5"
|
||||
type: "Dropout"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
dropout_param {
|
||||
dropout_ratio: 0.25
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prelu5"
|
||||
type: "PReLU"
|
||||
bottom: "conv5"
|
||||
top: "conv5"
|
||||
}
|
||||
|
||||
|
||||
layer {
|
||||
name: "conv6-1"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv6-2"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 4
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv6-3"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv5"
|
||||
top: "conv6-3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
#kernel_size: 1
|
||||
num_output: 10
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "prob1"
|
||||
type: "Softmax"
|
||||
bottom: "conv6-1"
|
||||
top: "prob1"
|
||||
}
|
||||
Binary file not shown.
File diff suppressed because it is too large
Load Diff
Binary file not shown.
@@ -1,995 +0,0 @@
|
||||
name: "LNet"
|
||||
input: "data"
|
||||
input_dim: 1
|
||||
input_dim: 15
|
||||
input_dim: 24
|
||||
input_dim: 24
|
||||
|
||||
layer {
|
||||
name: "slicer_data"
|
||||
type: "Slice"
|
||||
bottom: "data"
|
||||
top: "data241"
|
||||
top: "data242"
|
||||
top: "data243"
|
||||
top: "data244"
|
||||
top: "data245"
|
||||
slice_param {
|
||||
axis: 1
|
||||
slice_point: 3
|
||||
slice_point: 6
|
||||
slice_point: 9
|
||||
slice_point: 12
|
||||
}
|
||||
}
|
||||
layer {
|
||||
name: "conv1_1"
|
||||
type: "Convolution"
|
||||
bottom: "data241"
|
||||
top: "conv1_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_1"
|
||||
top: "conv1_1"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_1"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_1"
|
||||
top: "pool1_1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_1"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_1"
|
||||
top: "conv2_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_1"
|
||||
top: "conv2_1"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_1"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_1"
|
||||
top: "pool2_1"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_1"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_1"
|
||||
top: "conv3_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_1"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_1"
|
||||
top: "conv3_1"
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_2"
|
||||
type: "Convolution"
|
||||
bottom: "data242"
|
||||
top: "conv1_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_2"
|
||||
top: "conv1_2"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_2"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_2"
|
||||
top: "pool1_2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_2"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_2"
|
||||
top: "conv2_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_2"
|
||||
top: "conv2_2"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_2"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_2"
|
||||
top: "pool2_2"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_2"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_2"
|
||||
top: "conv3_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_2"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_2"
|
||||
top: "conv3_2"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_3"
|
||||
type: "Convolution"
|
||||
bottom: "data243"
|
||||
top: "conv1_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_3"
|
||||
top: "conv1_3"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_3"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_3"
|
||||
top: "pool1_3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_3"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_3"
|
||||
top: "conv2_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_3"
|
||||
top: "conv2_3"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_3"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_3"
|
||||
top: "pool2_3"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_3"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_3"
|
||||
top: "conv3_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_3"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_3"
|
||||
top: "conv3_3"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_4"
|
||||
type: "Convolution"
|
||||
bottom: "data244"
|
||||
top: "conv1_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_4"
|
||||
top: "conv1_4"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_4"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_4"
|
||||
top: "pool1_4"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_4"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_4"
|
||||
top: "conv2_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_4"
|
||||
top: "conv2_4"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_4"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_4"
|
||||
top: "pool2_4"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_4"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_4"
|
||||
top: "conv3_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_4"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_4"
|
||||
top: "conv3_4"
|
||||
}
|
||||
##########################
|
||||
##########################
|
||||
layer {
|
||||
name: "conv1_5"
|
||||
type: "Convolution"
|
||||
bottom: "data245"
|
||||
top: "conv1_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 28
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu1_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv1_5"
|
||||
top: "conv1_5"
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "pool1_5"
|
||||
type: "Pooling"
|
||||
bottom: "conv1_5"
|
||||
top: "pool1_5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
}
|
||||
|
||||
layer {
|
||||
name: "conv2_5"
|
||||
type: "Convolution"
|
||||
bottom: "pool1_5"
|
||||
top: "conv2_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 48
|
||||
kernel_size: 3
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu2_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv2_5"
|
||||
top: "conv2_5"
|
||||
}
|
||||
layer {
|
||||
name: "pool2_5"
|
||||
type: "Pooling"
|
||||
bottom: "conv2_5"
|
||||
top: "pool2_5"
|
||||
pooling_param {
|
||||
pool: MAX
|
||||
kernel_size: 3
|
||||
stride: 2
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "conv3_5"
|
||||
type: "Convolution"
|
||||
bottom: "pool2_5"
|
||||
top: "conv3_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
convolution_param {
|
||||
num_output: 64
|
||||
kernel_size: 2
|
||||
stride: 1
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu3_5"
|
||||
type: "PReLU"
|
||||
bottom: "conv3_5"
|
||||
top: "conv3_5"
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "concat"
|
||||
bottom: "conv3_1"
|
||||
bottom: "conv3_2"
|
||||
bottom: "conv3_3"
|
||||
bottom: "conv3_4"
|
||||
bottom: "conv3_5"
|
||||
top: "conv3"
|
||||
type: "Concat"
|
||||
concat_param {
|
||||
axis: 1
|
||||
}
|
||||
}
|
||||
##########################
|
||||
layer {
|
||||
name: "fc4"
|
||||
type: "InnerProduct"
|
||||
bottom: "conv3"
|
||||
top: "fc4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 256
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4"
|
||||
type: "PReLU"
|
||||
bottom: "fc4"
|
||||
top: "fc4"
|
||||
}
|
||||
############################
|
||||
layer {
|
||||
name: "fc4_1"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_1"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_1"
|
||||
top: "fc4_1"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_1"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_1"
|
||||
top: "fc5_1"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_2"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_2"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_2"
|
||||
top: "fc4_2"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_2"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_2"
|
||||
top: "fc5_2"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_3"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_3"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_3"
|
||||
top: "fc4_3"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_3"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_3"
|
||||
top: "fc5_3"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_4"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_4"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_4"
|
||||
top: "fc4_4"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_4"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_4"
|
||||
top: "fc5_4"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
layer {
|
||||
name: "fc4_5"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4"
|
||||
top: "fc4_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 64
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
layer {
|
||||
name: "prelu4_5"
|
||||
type: "PReLU"
|
||||
bottom: "fc4_5"
|
||||
top: "fc4_5"
|
||||
}
|
||||
layer {
|
||||
name: "fc5_5"
|
||||
type: "InnerProduct"
|
||||
bottom: "fc4_5"
|
||||
top: "fc5_5"
|
||||
param {
|
||||
lr_mult: 1
|
||||
decay_mult: 1
|
||||
}
|
||||
param {
|
||||
lr_mult: 2
|
||||
decay_mult: 1
|
||||
}
|
||||
inner_product_param {
|
||||
num_output: 2
|
||||
weight_filler {
|
||||
type: "xavier"
|
||||
#type: "constant"
|
||||
#value: 0
|
||||
}
|
||||
bias_filler {
|
||||
type: "constant"
|
||||
value: 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#########################
|
||||
|
||||
@@ -1,696 +0,0 @@
|
||||
# coding: utf-8
|
||||
import os
|
||||
import mxnet as mx
|
||||
import numpy as np
|
||||
import math
|
||||
import cv2
|
||||
from multiprocessing import Pool
|
||||
from itertools import repeat
|
||||
from itertools import izip
|
||||
from helper import nms, adjust_input, generate_bbox, detect_first_stage_warpper
|
||||
|
||||
|
||||
class MtcnnDetector(object):
|
||||
"""
|
||||
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Neural Networks
|
||||
see https://github.com/kpzhang93/MTCNN_face_detection_alignment
|
||||
this is a mxnet version
|
||||
"""
|
||||
def __init__(self,
|
||||
model_folder='.',
|
||||
minsize=20,
|
||||
threshold=[0.6, 0.7, 0.8],
|
||||
factor=0.709,
|
||||
num_worker=1,
|
||||
accurate_landmark=False,
|
||||
ctx=mx.cpu()):
|
||||
"""
|
||||
Initialize the detector
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
model_folder : string
|
||||
path for the models
|
||||
minsize : float number
|
||||
minimal face to detect
|
||||
threshold : float number
|
||||
detect threshold for 3 stages
|
||||
factor: float number
|
||||
scale factor for image pyramid
|
||||
num_worker: int number
|
||||
number of processes we use for first stage
|
||||
accurate_landmark: bool
|
||||
use accurate landmark localization or not
|
||||
|
||||
"""
|
||||
self.num_worker = num_worker
|
||||
self.accurate_landmark = accurate_landmark
|
||||
|
||||
# load 4 models from folder
|
||||
models = ['det1', 'det2', 'det3', 'det4']
|
||||
models = [os.path.join(model_folder, f) for f in models]
|
||||
|
||||
self.PNets = []
|
||||
for i in range(num_worker):
|
||||
workner_net = mx.model.FeedForward.load(models[0], 1, ctx=ctx)
|
||||
self.PNets.append(workner_net)
|
||||
|
||||
#self.Pool = Pool(num_worker)
|
||||
|
||||
self.RNet = mx.model.FeedForward.load(models[1], 1, ctx=ctx)
|
||||
self.ONet = mx.model.FeedForward.load(models[2], 1, ctx=ctx)
|
||||
self.LNet = mx.model.FeedForward.load(models[3], 1, ctx=ctx)
|
||||
|
||||
self.minsize = float(minsize)
|
||||
self.factor = float(factor)
|
||||
self.threshold = threshold
|
||||
|
||||
def convert_to_square(self, bbox):
|
||||
"""
|
||||
convert bbox to square
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bbox: numpy array , shape n x 5
|
||||
input bbox
|
||||
|
||||
Returns:
|
||||
-------
|
||||
square bbox
|
||||
"""
|
||||
square_bbox = bbox.copy()
|
||||
|
||||
h = bbox[:, 3] - bbox[:, 1] + 1
|
||||
w = bbox[:, 2] - bbox[:, 0] + 1
|
||||
max_side = np.maximum(h, w)
|
||||
square_bbox[:, 0] = bbox[:, 0] + w * 0.5 - max_side * 0.5
|
||||
square_bbox[:, 1] = bbox[:, 1] + h * 0.5 - max_side * 0.5
|
||||
square_bbox[:, 2] = square_bbox[:, 0] + max_side - 1
|
||||
square_bbox[:, 3] = square_bbox[:, 1] + max_side - 1
|
||||
return square_bbox
|
||||
|
||||
def calibrate_box(self, bbox, reg):
|
||||
"""
|
||||
calibrate bboxes
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bbox: numpy array, shape n x 5
|
||||
input bboxes
|
||||
reg: numpy array, shape n x 4
|
||||
bboxex adjustment
|
||||
|
||||
Returns:
|
||||
-------
|
||||
bboxes after refinement
|
||||
|
||||
"""
|
||||
w = bbox[:, 2] - bbox[:, 0] + 1
|
||||
w = np.expand_dims(w, 1)
|
||||
h = bbox[:, 3] - bbox[:, 1] + 1
|
||||
h = np.expand_dims(h, 1)
|
||||
reg_m = np.hstack([w, h, w, h])
|
||||
aug = reg_m * reg
|
||||
bbox[:, 0:4] = bbox[:, 0:4] + aug
|
||||
return bbox
|
||||
|
||||
def pad(self, bboxes, w, h):
|
||||
"""
|
||||
pad the the bboxes, alse restrict the size of it
|
||||
|
||||
Parameters:
|
||||
----------
|
||||
bboxes: numpy array, n x 5
|
||||
input bboxes
|
||||
w: float number
|
||||
width of the input image
|
||||
h: float number
|
||||
height of the input image
|
||||
Returns :
|
||||
------s
|
||||
dy, dx : numpy array, n x 1
|
||||
start point of the bbox in target image
|
||||
edy, edx : numpy array, n x 1
|
||||
end point of the bbox in target image
|
||||
y, x : numpy array, n x 1
|
||||
start point of the bbox in original image
|
||||
ex, ex : numpy array, n x 1
|
||||
end point of the bbox in original image
|
||||
tmph, tmpw: numpy array, n x 1
|
||||
height and width of the bbox
|
||||
|
||||
"""
|
||||
tmpw, tmph = bboxes[:, 2] - bboxes[:, 0] + 1, bboxes[:,
|
||||
3] - bboxes[:,
|
||||
1] + 1
|
||||
num_box = bboxes.shape[0]
|
||||
|
||||
dx, dy = np.zeros((num_box, )), np.zeros((num_box, ))
|
||||
edx, edy = tmpw.copy() - 1, tmph.copy() - 1
|
||||
|
||||
x, y, ex, ey = bboxes[:, 0], bboxes[:, 1], bboxes[:, 2], bboxes[:, 3]
|
||||
|
||||
tmp_index = np.where(ex > w - 1)
|
||||
edx[tmp_index] = tmpw[tmp_index] + w - 2 - ex[tmp_index]
|
||||
ex[tmp_index] = w - 1
|
||||
|
||||
tmp_index = np.where(ey > h - 1)
|
||||
edy[tmp_index] = tmph[tmp_index] + h - 2 - ey[tmp_index]
|
||||
ey[tmp_index] = h - 1
|
||||
|
||||
tmp_index = np.where(x < 0)
|
||||
dx[tmp_index] = 0 - x[tmp_index]
|
||||
x[tmp_index] = 0
|
||||
|
||||
tmp_index = np.where(y < 0)
|
||||
dy[tmp_index] = 0 - y[tmp_index]
|
||||
y[tmp_index] = 0
|
||||
|
||||
return_list = [dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph]
|
||||
return_list = [item.astype(np.int32) for item in return_list]
|
||||
|
||||
return return_list
|
||||
|
||||
def slice_index(self, number):
|
||||
"""
|
||||
slice the index into (n,n,m), m < n
|
||||
Parameters:
|
||||
----------
|
||||
number: int number
|
||||
number
|
||||
"""
|
||||
def chunks(l, n):
|
||||
"""Yield successive n-sized chunks from l."""
|
||||
for i in range(0, len(l), n):
|
||||
yield l[i:i + n]
|
||||
|
||||
num_list = range(number)
|
||||
return list(chunks(num_list, self.num_worker))
|
||||
|
||||
def detect_face_limited(self, img, det_type=2):
|
||||
height, width, _ = img.shape
|
||||
if det_type >= 2:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 24, 24) is the input shape for RNet
|
||||
input_buf = np.zeros((num_box, 3, 24, 24), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
||||
tmp[dy[i]:edy[i] + 1,
|
||||
dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (24, 24)))
|
||||
|
||||
output = self.RNet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[1][:, 1] > self.threshold[1])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[1][passed, 1].reshape((-1, ))
|
||||
reg = output[0][passed]
|
||||
|
||||
# nms
|
||||
pick = nms(total_boxes, 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
total_boxes = self.calibrate_box(total_boxes, reg[pick])
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
else:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
num_box = total_boxes.shape[0]
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 48, 48) is the input shape for ONet
|
||||
input_buf = np.zeros((num_box, 3, 48, 48), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.float32)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (48, 48)))
|
||||
|
||||
output = self.ONet.predict(input_buf)
|
||||
#print(output[2])
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[2][:, 1] > self.threshold[2])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[2][passed, 1].reshape((-1, ))
|
||||
reg = output[1][passed]
|
||||
points = output[0][passed]
|
||||
|
||||
# compute landmark points
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
points[:, 0:5] = np.expand_dims(
|
||||
total_boxes[:, 0], 1) + np.expand_dims(bbw, 1) * points[:, 0:5]
|
||||
points[:, 5:10] = np.expand_dims(
|
||||
total_boxes[:, 1], 1) + np.expand_dims(bbh, 1) * points[:, 5:10]
|
||||
|
||||
# nms
|
||||
total_boxes = self.calibrate_box(total_boxes, reg)
|
||||
pick = nms(total_boxes, 0.7, 'Min')
|
||||
total_boxes = total_boxes[pick]
|
||||
points = points[pick]
|
||||
|
||||
if not self.accurate_landmark:
|
||||
return total_boxes, points
|
||||
|
||||
#############################################
|
||||
# extended stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
patchw = np.maximum(total_boxes[:, 2] - total_boxes[:, 0] + 1,
|
||||
total_boxes[:, 3] - total_boxes[:, 1] + 1)
|
||||
patchw = np.round(patchw * 0.25)
|
||||
|
||||
# make it even
|
||||
patchw[np.where(np.mod(patchw, 2) == 1)] += 1
|
||||
|
||||
input_buf = np.zeros((num_box, 15, 24, 24), dtype=np.float32)
|
||||
for i in range(5):
|
||||
x, y = points[:, i], points[:, i + 5]
|
||||
x, y = np.round(x - 0.5 * patchw), np.round(y - 0.5 * patchw)
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(
|
||||
np.vstack([x, y, x + patchw - 1, y + patchw - 1]).T, width,
|
||||
height)
|
||||
for j in range(num_box):
|
||||
tmpim = np.zeros((tmpw[j], tmpw[j], 3), dtype=np.float32)
|
||||
tmpim[dy[j]:edy[j] + 1,
|
||||
dx[j]:edx[j] + 1, :] = img[y[j]:ey[j] + 1,
|
||||
x[j]:ex[j] + 1, :]
|
||||
input_buf[j, i * 3:i * 3 + 3, :, :] = adjust_input(
|
||||
cv2.resize(tmpim, (24, 24)))
|
||||
|
||||
output = self.LNet.predict(input_buf)
|
||||
|
||||
pointx = np.zeros((num_box, 5))
|
||||
pointy = np.zeros((num_box, 5))
|
||||
|
||||
for k in range(5):
|
||||
# do not make a large movement
|
||||
tmp_index = np.where(np.abs(output[k] - 0.5) > 0.35)
|
||||
output[k][tmp_index[0]] = 0.5
|
||||
|
||||
pointx[:, k] = np.round(points[:, k] -
|
||||
0.5 * patchw) + output[k][:, 0] * patchw
|
||||
pointy[:, k] = np.round(points[:, k + 5] -
|
||||
0.5 * patchw) + output[k][:, 1] * patchw
|
||||
|
||||
points = np.hstack([pointx, pointy])
|
||||
points = points.astype(np.int32)
|
||||
|
||||
return total_boxes, points
|
||||
|
||||
def detect_face(self, img, det_type=0):
|
||||
"""
|
||||
detect face over img
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order of shape (1, 3, n, m)
|
||||
input image
|
||||
Retures:
|
||||
-------
|
||||
bboxes: numpy array, n x 5 (x1,y2,x2,y2,score)
|
||||
bboxes
|
||||
points: numpy array, n x 10 (x1, x2 ... x5, y1, y2 ..y5)
|
||||
landmarks
|
||||
"""
|
||||
|
||||
# check input
|
||||
height, width, _ = img.shape
|
||||
if det_type == 0:
|
||||
MIN_DET_SIZE = 12
|
||||
|
||||
if img is None:
|
||||
return None
|
||||
|
||||
# only works for color image
|
||||
if len(img.shape) != 3:
|
||||
return None
|
||||
|
||||
# detected boxes
|
||||
total_boxes = []
|
||||
|
||||
minl = min(height, width)
|
||||
|
||||
# get all the valid scales
|
||||
scales = []
|
||||
m = MIN_DET_SIZE / self.minsize
|
||||
minl *= m
|
||||
factor_count = 0
|
||||
while minl > MIN_DET_SIZE:
|
||||
scales.append(m * self.factor**factor_count)
|
||||
minl *= self.factor
|
||||
factor_count += 1
|
||||
|
||||
#############################################
|
||||
# first stage
|
||||
#############################################
|
||||
#for scale in scales:
|
||||
# return_boxes = self.detect_first_stage(img, scale, 0)
|
||||
# if return_boxes is not None:
|
||||
# total_boxes.append(return_boxes)
|
||||
|
||||
sliced_index = self.slice_index(len(scales))
|
||||
total_boxes = []
|
||||
for batch in sliced_index:
|
||||
#local_boxes = self.Pool.map( detect_first_stage_warpper, \
|
||||
# izip(repeat(img), self.PNets[:len(batch)], [scales[i] for i in batch], repeat(self.threshold[0])) )
|
||||
local_boxes = map( detect_first_stage_warpper, \
|
||||
izip(repeat(img), self.PNets[:len(batch)], [scales[i] for i in batch], repeat(self.threshold[0])) )
|
||||
total_boxes.extend(local_boxes)
|
||||
|
||||
# remove the Nones
|
||||
total_boxes = [i for i in total_boxes if i is not None]
|
||||
|
||||
if len(total_boxes) == 0:
|
||||
return None
|
||||
|
||||
total_boxes = np.vstack(total_boxes)
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
# merge the detection from first stage
|
||||
pick = nms(total_boxes[:, 0:5], 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
|
||||
# refine the bboxes
|
||||
total_boxes = np.vstack([
|
||||
total_boxes[:, 0] + total_boxes[:, 5] * bbw,
|
||||
total_boxes[:, 1] + total_boxes[:, 6] * bbh,
|
||||
total_boxes[:, 2] + total_boxes[:, 7] * bbw,
|
||||
total_boxes[:, 3] + total_boxes[:, 8] * bbh, total_boxes[:, 4]
|
||||
])
|
||||
|
||||
total_boxes = total_boxes.T
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
else:
|
||||
total_boxes = np.array(
|
||||
[[0.0, 0.0, img.shape[1], img.shape[0], 0.9]],
|
||||
dtype=np.float32)
|
||||
|
||||
#############################################
|
||||
# second stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 24, 24) is the input shape for RNet
|
||||
input_buf = np.zeros((num_box, 3, 24, 24), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (24, 24)))
|
||||
|
||||
output = self.RNet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[1][:, 1] > self.threshold[1])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[1][passed, 1].reshape((-1, ))
|
||||
reg = output[0][passed]
|
||||
|
||||
# nms
|
||||
pick = nms(total_boxes, 0.7, 'Union')
|
||||
total_boxes = total_boxes[pick]
|
||||
total_boxes = self.calibrate_box(total_boxes, reg[pick])
|
||||
total_boxes = self.convert_to_square(total_boxes)
|
||||
total_boxes[:, 0:4] = np.round(total_boxes[:, 0:4])
|
||||
|
||||
#############################################
|
||||
# third stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
|
||||
# pad the bbox
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw,
|
||||
tmph] = self.pad(total_boxes, width, height)
|
||||
# (3, 48, 48) is the input shape for ONet
|
||||
input_buf = np.zeros((num_box, 3, 48, 48), dtype=np.float32)
|
||||
|
||||
for i in range(num_box):
|
||||
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.float32)
|
||||
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = img[y[i]:ey[i] + 1,
|
||||
x[i]:ex[i] + 1, :]
|
||||
input_buf[i, :, :, :] = adjust_input(cv2.resize(tmp, (48, 48)))
|
||||
|
||||
output = self.ONet.predict(input_buf)
|
||||
|
||||
# filter the total_boxes with threshold
|
||||
passed = np.where(output[2][:, 1] > self.threshold[2])
|
||||
total_boxes = total_boxes[passed]
|
||||
|
||||
if total_boxes.size == 0:
|
||||
return None
|
||||
|
||||
total_boxes[:, 4] = output[2][passed, 1].reshape((-1, ))
|
||||
reg = output[1][passed]
|
||||
points = output[0][passed]
|
||||
|
||||
# compute landmark points
|
||||
bbw = total_boxes[:, 2] - total_boxes[:, 0] + 1
|
||||
bbh = total_boxes[:, 3] - total_boxes[:, 1] + 1
|
||||
points[:, 0:5] = np.expand_dims(
|
||||
total_boxes[:, 0], 1) + np.expand_dims(bbw, 1) * points[:, 0:5]
|
||||
points[:, 5:10] = np.expand_dims(
|
||||
total_boxes[:, 1], 1) + np.expand_dims(bbh, 1) * points[:, 5:10]
|
||||
|
||||
# nms
|
||||
total_boxes = self.calibrate_box(total_boxes, reg)
|
||||
pick = nms(total_boxes, 0.7, 'Min')
|
||||
total_boxes = total_boxes[pick]
|
||||
points = points[pick]
|
||||
|
||||
if not self.accurate_landmark:
|
||||
return total_boxes, points
|
||||
|
||||
#############################################
|
||||
# extended stage
|
||||
#############################################
|
||||
num_box = total_boxes.shape[0]
|
||||
patchw = np.maximum(total_boxes[:, 2] - total_boxes[:, 0] + 1,
|
||||
total_boxes[:, 3] - total_boxes[:, 1] + 1)
|
||||
patchw = np.round(patchw * 0.25)
|
||||
|
||||
# make it even
|
||||
patchw[np.where(np.mod(patchw, 2) == 1)] += 1
|
||||
|
||||
input_buf = np.zeros((num_box, 15, 24, 24), dtype=np.float32)
|
||||
for i in range(5):
|
||||
x, y = points[:, i], points[:, i + 5]
|
||||
x, y = np.round(x - 0.5 * patchw), np.round(y - 0.5 * patchw)
|
||||
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(
|
||||
np.vstack([x, y, x + patchw - 1, y + patchw - 1]).T, width,
|
||||
height)
|
||||
for j in range(num_box):
|
||||
tmpim = np.zeros((tmpw[j], tmpw[j], 3), dtype=np.float32)
|
||||
tmpim[dy[j]:edy[j] + 1,
|
||||
dx[j]:edx[j] + 1, :] = img[y[j]:ey[j] + 1,
|
||||
x[j]:ex[j] + 1, :]
|
||||
input_buf[j, i * 3:i * 3 + 3, :, :] = adjust_input(
|
||||
cv2.resize(tmpim, (24, 24)))
|
||||
|
||||
output = self.LNet.predict(input_buf)
|
||||
|
||||
pointx = np.zeros((num_box, 5))
|
||||
pointy = np.zeros((num_box, 5))
|
||||
|
||||
for k in range(5):
|
||||
# do not make a large movement
|
||||
tmp_index = np.where(np.abs(output[k] - 0.5) > 0.35)
|
||||
output[k][tmp_index[0]] = 0.5
|
||||
|
||||
pointx[:, k] = np.round(points[:, k] -
|
||||
0.5 * patchw) + output[k][:, 0] * patchw
|
||||
pointy[:, k] = np.round(points[:, k + 5] -
|
||||
0.5 * patchw) + output[k][:, 1] * patchw
|
||||
|
||||
points = np.hstack([pointx, pointy])
|
||||
points = points.astype(np.int32)
|
||||
|
||||
return total_boxes, points
|
||||
|
||||
def list2colmatrix(self, pts_list):
|
||||
"""
|
||||
convert list to column matrix
|
||||
Parameters:
|
||||
----------
|
||||
pts_list:
|
||||
input list
|
||||
Retures:
|
||||
-------
|
||||
colMat:
|
||||
|
||||
"""
|
||||
assert len(pts_list) > 0
|
||||
colMat = []
|
||||
for i in range(len(pts_list)):
|
||||
colMat.append(pts_list[i][0])
|
||||
colMat.append(pts_list[i][1])
|
||||
colMat = np.matrix(colMat).transpose()
|
||||
return colMat
|
||||
|
||||
def find_tfrom_between_shapes(self, from_shape, to_shape):
|
||||
"""
|
||||
find transform between shapes
|
||||
Parameters:
|
||||
----------
|
||||
from_shape:
|
||||
to_shape:
|
||||
Retures:
|
||||
-------
|
||||
tran_m:
|
||||
tran_b:
|
||||
"""
|
||||
assert from_shape.shape[0] == to_shape.shape[
|
||||
0] and from_shape.shape[0] % 2 == 0
|
||||
|
||||
sigma_from = 0.0
|
||||
sigma_to = 0.0
|
||||
cov = np.matrix([[0.0, 0.0], [0.0, 0.0]])
|
||||
|
||||
# compute the mean and cov
|
||||
from_shape_points = from_shape.reshape(from_shape.shape[0] / 2, 2)
|
||||
to_shape_points = to_shape.reshape(to_shape.shape[0] / 2, 2)
|
||||
mean_from = from_shape_points.mean(axis=0)
|
||||
mean_to = to_shape_points.mean(axis=0)
|
||||
|
||||
for i in range(from_shape_points.shape[0]):
|
||||
temp_dis = np.linalg.norm(from_shape_points[i] - mean_from)
|
||||
sigma_from += temp_dis * temp_dis
|
||||
temp_dis = np.linalg.norm(to_shape_points[i] - mean_to)
|
||||
sigma_to += temp_dis * temp_dis
|
||||
cov += (to_shape_points[i].transpose() -
|
||||
mean_to.transpose()) * (from_shape_points[i] - mean_from)
|
||||
|
||||
sigma_from = sigma_from / to_shape_points.shape[0]
|
||||
sigma_to = sigma_to / to_shape_points.shape[0]
|
||||
cov = cov / to_shape_points.shape[0]
|
||||
|
||||
# compute the affine matrix
|
||||
s = np.matrix([[1.0, 0.0], [0.0, 1.0]])
|
||||
u, d, vt = np.linalg.svd(cov)
|
||||
|
||||
if np.linalg.det(cov) < 0:
|
||||
if d[1] < d[0]:
|
||||
s[1, 1] = -1
|
||||
else:
|
||||
s[0, 0] = -1
|
||||
r = u * s * vt
|
||||
c = 1.0
|
||||
if sigma_from != 0:
|
||||
c = 1.0 / sigma_from * np.trace(np.diag(d) * s)
|
||||
|
||||
tran_b = mean_to.transpose() - c * r * mean_from.transpose()
|
||||
tran_m = c * r
|
||||
|
||||
return tran_m, tran_b
|
||||
|
||||
def extract_image_chips(self, img, points, desired_size=256, padding=0):
|
||||
"""
|
||||
crop and align face
|
||||
Parameters:
|
||||
----------
|
||||
img: numpy array, bgr order of shape (1, 3, n, m)
|
||||
input image
|
||||
points: numpy array, n x 10 (x1, x2 ... x5, y1, y2 ..y5)
|
||||
desired_size: default 256
|
||||
padding: default 0
|
||||
Retures:
|
||||
-------
|
||||
crop_imgs: list, n
|
||||
cropped and aligned faces
|
||||
"""
|
||||
crop_imgs = []
|
||||
for p in points:
|
||||
shape = []
|
||||
for k in range(len(p) / 2):
|
||||
shape.append(p[k])
|
||||
shape.append(p[k + 5])
|
||||
|
||||
if padding > 0:
|
||||
padding = padding
|
||||
else:
|
||||
padding = 0
|
||||
# average positions of face points
|
||||
mean_face_shape_x = [
|
||||
0.224152, 0.75610125, 0.490127, 0.254149, 0.726104
|
||||
]
|
||||
mean_face_shape_y = [
|
||||
0.2119465, 0.2119465, 0.628106, 0.780233, 0.780233
|
||||
]
|
||||
|
||||
from_points = []
|
||||
to_points = []
|
||||
|
||||
for i in range(len(shape) / 2):
|
||||
x = (padding + mean_face_shape_x[i]) / (2 * padding +
|
||||
1) * desired_size
|
||||
y = (padding + mean_face_shape_y[i]) / (2 * padding +
|
||||
1) * desired_size
|
||||
to_points.append([x, y])
|
||||
from_points.append([shape[2 * i], shape[2 * i + 1]])
|
||||
|
||||
# convert the points to Mat
|
||||
from_mat = self.list2colmatrix(from_points)
|
||||
to_mat = self.list2colmatrix(to_points)
|
||||
|
||||
# compute the similar transfrom
|
||||
tran_m, tran_b = self.find_tfrom_between_shapes(from_mat, to_mat)
|
||||
|
||||
probe_vec = np.matrix([1.0, 0.0]).transpose()
|
||||
probe_vec = tran_m * probe_vec
|
||||
|
||||
scale = np.linalg.norm(probe_vec)
|
||||
angle = 180.0 / math.pi * math.atan2(probe_vec[1, 0], probe_vec[0,
|
||||
0])
|
||||
|
||||
from_center = [(shape[0] + shape[2]) / 2.0,
|
||||
(shape[1] + shape[3]) / 2.0]
|
||||
to_center = [0, 0]
|
||||
to_center[1] = desired_size * 0.4
|
||||
to_center[0] = desired_size * 0.5
|
||||
|
||||
ex = to_center[0] - from_center[0]
|
||||
ey = to_center[1] - from_center[1]
|
||||
|
||||
rot_mat = cv2.getRotationMatrix2D((from_center[0], from_center[1]),
|
||||
-1 * angle, scale)
|
||||
rot_mat[0][2] += ex
|
||||
rot_mat[1][2] += ey
|
||||
|
||||
chips = cv2.warpAffine(img, rot_mat, (desired_size, desired_size))
|
||||
crop_imgs.append(chips)
|
||||
|
||||
return crop_imgs
|
||||
@@ -1,39 +0,0 @@
|
||||
import face_model
|
||||
import argparse
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import datetime
|
||||
|
||||
parser = argparse.ArgumentParser(description='face model test')
|
||||
# general
|
||||
parser.add_argument('--image-size', default='112,112', help='')
|
||||
parser.add_argument('--image', default='Tom_Hanks_54745.png', help='')
|
||||
parser.add_argument('--model',
|
||||
default='model/model,0',
|
||||
help='path to load model.')
|
||||
parser.add_argument('--gpu', default=0, type=int, help='gpu id')
|
||||
parser.add_argument(
|
||||
'--det',
|
||||
default=0,
|
||||
type=int,
|
||||
help='mtcnn option, 1 means using R+O, 0 means detect from begining')
|
||||
args = parser.parse_args()
|
||||
|
||||
model = face_model.FaceModel(args)
|
||||
#img = cv2.imread('Tom_Hanks_54745.png')
|
||||
img = cv2.imread(args.image)
|
||||
img = model.get_input(img)
|
||||
#f1 = model.get_feature(img)
|
||||
#print(f1[0:10])
|
||||
for _ in range(5):
|
||||
gender, age = model.get_ga(img)
|
||||
time_now = datetime.datetime.now()
|
||||
count = 200
|
||||
for _ in range(count):
|
||||
gender, age = model.get_ga(img)
|
||||
time_now2 = datetime.datetime.now()
|
||||
diff = time_now2 - time_now
|
||||
print('time cost', diff.total_seconds() / count)
|
||||
print('gender is', gender)
|
||||
print('age is', age)
|
||||
@@ -1,420 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import sys
|
||||
import math
|
||||
import random
|
||||
import logging
|
||||
import pickle
|
||||
import numpy as np
|
||||
import sklearn
|
||||
from data import FaceImageIter
|
||||
import mxnet as mx
|
||||
from mxnet import ndarray as nd
|
||||
import argparse
|
||||
import mxnet.optimizer as optimizer
|
||||
sys.path.append(os.path.join(os.path.dirname(__file__), 'common'))
|
||||
#import face_image
|
||||
import fresnet
|
||||
import fmobilenet
|
||||
|
||||
logger = logging.getLogger()
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
AGE = 100
|
||||
|
||||
args = None
|
||||
|
||||
|
||||
class AccMetric(mx.metric.EvalMetric):
|
||||
def __init__(self):
|
||||
self.axis = 1
|
||||
super(AccMetric, self).__init__('acc',
|
||||
axis=self.axis,
|
||||
output_names=None,
|
||||
label_names=None)
|
||||
self.losses = []
|
||||
self.count = 0
|
||||
|
||||
def update(self, labels, preds):
|
||||
self.count += 1
|
||||
label = labels[0].asnumpy()[:, 0:1]
|
||||
pred_label = preds[-1].asnumpy()[:, 0:2]
|
||||
pred_label = np.argmax(pred_label, axis=self.axis)
|
||||
pred_label = pred_label.astype('int32').flatten()
|
||||
label = label.astype('int32').flatten()
|
||||
assert label.shape == pred_label.shape
|
||||
self.sum_metric += (pred_label.flat == label.flat).sum()
|
||||
self.num_inst += len(pred_label.flat)
|
||||
|
||||
|
||||
class LossValueMetric(mx.metric.EvalMetric):
|
||||
def __init__(self):
|
||||
self.axis = 1
|
||||
super(LossValueMetric, self).__init__('lossvalue',
|
||||
axis=self.axis,
|
||||
output_names=None,
|
||||
label_names=None)
|
||||
self.losses = []
|
||||
|
||||
def update(self, labels, preds):
|
||||
loss = preds[-1].asnumpy()[0]
|
||||
self.sum_metric += loss
|
||||
self.num_inst += 1.0
|
||||
gt_label = preds[-2].asnumpy()
|
||||
#print(gt_label)
|
||||
|
||||
|
||||
class MAEMetric(mx.metric.EvalMetric):
|
||||
def __init__(self):
|
||||
self.axis = 1
|
||||
super(MAEMetric, self).__init__('MAE',
|
||||
axis=self.axis,
|
||||
output_names=None,
|
||||
label_names=None)
|
||||
self.losses = []
|
||||
self.count = 0
|
||||
|
||||
def update(self, labels, preds):
|
||||
self.count += 1
|
||||
label = labels[0].asnumpy()
|
||||
label_age = np.count_nonzero(label[:, 1:], axis=1)
|
||||
pred_age = np.zeros(label_age.shape, dtype=np.int)
|
||||
#pred_age = np.zeros( label_age.shape, dtype=np.float32)
|
||||
pred = preds[-1].asnumpy()
|
||||
for i in range(AGE):
|
||||
_pred = pred[:, 2 + i * 2:4 + i * 2]
|
||||
_pred = np.argmax(_pred, axis=1)
|
||||
#pred = pred[:,1]
|
||||
pred_age += _pred
|
||||
#pred_age = pred_age.astype(np.int)
|
||||
mae = np.mean(np.abs(label_age - pred_age))
|
||||
self.sum_metric += mae
|
||||
self.num_inst += 1.0
|
||||
|
||||
|
||||
class CUMMetric(mx.metric.EvalMetric):
|
||||
def __init__(self, n=5):
|
||||
self.axis = 1
|
||||
self.n = n
|
||||
super(CUMMetric, self).__init__('CUM_%d' % n,
|
||||
axis=self.axis,
|
||||
output_names=None,
|
||||
label_names=None)
|
||||
self.losses = []
|
||||
self.count = 0
|
||||
|
||||
def update(self, labels, preds):
|
||||
self.count += 1
|
||||
label = labels[0].asnumpy()
|
||||
label_age = np.count_nonzero(label[:, 1:], axis=1)
|
||||
pred_age = np.zeros(label_age.shape, dtype=np.int)
|
||||
pred = preds[-1].asnumpy()
|
||||
for i in range(AGE):
|
||||
_pred = pred[:, 2 + i * 2:4 + i * 2]
|
||||
_pred = np.argmax(_pred, axis=1)
|
||||
#pred = pred[:,1]
|
||||
pred_age += _pred
|
||||
diff = np.abs(label_age - pred_age)
|
||||
cum = np.sum((diff < self.n))
|
||||
self.sum_metric += cum
|
||||
self.num_inst += len(label_age)
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description='Train face network')
|
||||
# general
|
||||
parser.add_argument('--data-dir',
|
||||
default='',
|
||||
help='training set directory')
|
||||
parser.add_argument('--prefix',
|
||||
default='../model/model',
|
||||
help='directory to save model.')
|
||||
parser.add_argument('--pretrained',
|
||||
default='',
|
||||
help='pretrained model to load')
|
||||
parser.add_argument(
|
||||
'--ckpt',
|
||||
type=int,
|
||||
default=1,
|
||||
help=
|
||||
'checkpoint saving option. 0: discard saving. 1: save when necessary. 2: always save'
|
||||
)
|
||||
parser.add_argument('--loss-type', type=int, default=4, help='loss type')
|
||||
parser.add_argument(
|
||||
'--verbose',
|
||||
type=int,
|
||||
default=2000,
|
||||
help='do verification testing and model saving every verbose batches')
|
||||
parser.add_argument('--max-steps',
|
||||
type=int,
|
||||
default=0,
|
||||
help='max training batches')
|
||||
parser.add_argument('--end-epoch',
|
||||
type=int,
|
||||
default=100000,
|
||||
help='training epoch size.')
|
||||
parser.add_argument('--network', default='r50', help='specify network')
|
||||
parser.add_argument('--image-size',
|
||||
default='112,112',
|
||||
help='specify input image height and width')
|
||||
parser.add_argument('--version-input',
|
||||
type=int,
|
||||
default=1,
|
||||
help='network input config')
|
||||
parser.add_argument('--version-output',
|
||||
type=str,
|
||||
default='GAP',
|
||||
help='network embedding output config')
|
||||
parser.add_argument('--version-act',
|
||||
type=str,
|
||||
default='prelu',
|
||||
help='network activation config')
|
||||
parser.add_argument('--multiplier', type=float, default=1.0, help='')
|
||||
parser.add_argument('--lr',
|
||||
type=float,
|
||||
default=0.1,
|
||||
help='start learning rate')
|
||||
parser.add_argument('--lr-steps',
|
||||
type=str,
|
||||
default='',
|
||||
help='steps of lr changing')
|
||||
parser.add_argument('--wd',
|
||||
type=float,
|
||||
default=0.0005,
|
||||
help='weight decay')
|
||||
parser.add_argument('--bn-mom', type=float, default=0.9, help='bn mom')
|
||||
parser.add_argument('--mom', type=float, default=0.9, help='momentum')
|
||||
parser.add_argument('--per-batch-size',
|
||||
type=int,
|
||||
default=128,
|
||||
help='batch size in each context')
|
||||
parser.add_argument('--rand-mirror',
|
||||
type=int,
|
||||
default=1,
|
||||
help='if do random mirror in training')
|
||||
parser.add_argument('--cutoff', type=int, default=0, help='cut off aug')
|
||||
parser.add_argument('--color',
|
||||
type=int,
|
||||
default=0,
|
||||
help='color jittering aug')
|
||||
parser.add_argument('--ce-loss',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help='if output ce loss')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def get_symbol(args, arg_params, aux_params):
|
||||
data_shape = (args.image_channel, args.image_h, args.image_w)
|
||||
image_shape = ",".join([str(x) for x in data_shape])
|
||||
margin_symbols = []
|
||||
if args.network[0] == 'm':
|
||||
fc1 = fmobilenet.get_symbol(AGE * 2 + 2,
|
||||
multiplier=args.multiplier,
|
||||
version_input=args.version_input,
|
||||
version_output=args.version_output)
|
||||
else:
|
||||
fc1 = fresnet.get_symbol(AGE * 2 + 2,
|
||||
args.num_layers,
|
||||
version_input=args.version_input,
|
||||
version_output=args.version_output)
|
||||
label = mx.symbol.Variable('softmax_label')
|
||||
gender_label = mx.symbol.slice_axis(data=label, axis=1, begin=0, end=1)
|
||||
gender_label = mx.symbol.reshape(gender_label,
|
||||
shape=(args.per_batch_size, ))
|
||||
gender_fc1 = mx.symbol.slice_axis(data=fc1, axis=1, begin=0, end=2)
|
||||
#gender_fc7 = mx.sym.FullyConnected(data=gender_fc1, num_hidden=2, name='gender_fc7')
|
||||
gender_softmax = mx.symbol.SoftmaxOutput(data=gender_fc1,
|
||||
label=gender_label,
|
||||
name='gender_softmax',
|
||||
normalization='valid',
|
||||
use_ignore=True,
|
||||
ignore_label=9999)
|
||||
outs = [gender_softmax]
|
||||
for i in range(AGE):
|
||||
age_label = mx.symbol.slice_axis(data=label,
|
||||
axis=1,
|
||||
begin=i + 1,
|
||||
end=i + 2)
|
||||
age_label = mx.symbol.reshape(age_label, shape=(args.per_batch_size, ))
|
||||
age_fc1 = mx.symbol.slice_axis(data=fc1,
|
||||
axis=1,
|
||||
begin=2 + i * 2,
|
||||
end=4 + i * 2)
|
||||
#age_fc7 = mx.sym.FullyConnected(data=age_fc1, num_hidden=2, name='age_fc7_%i'%i)
|
||||
age_softmax = mx.symbol.SoftmaxOutput(data=age_fc1,
|
||||
label=age_label,
|
||||
name='age_softmax_%d' % i,
|
||||
normalization='valid',
|
||||
grad_scale=1)
|
||||
outs.append(age_softmax)
|
||||
outs.append(mx.sym.BlockGrad(fc1))
|
||||
|
||||
out = mx.symbol.Group(outs)
|
||||
return (out, arg_params, aux_params)
|
||||
|
||||
|
||||
def train_net(args):
|
||||
ctx = []
|
||||
cvd = os.environ['CUDA_VISIBLE_DEVICES'].strip()
|
||||
if len(cvd) > 0:
|
||||
for i in range(len(cvd.split(','))):
|
||||
ctx.append(mx.gpu(i))
|
||||
if len(ctx) == 0:
|
||||
ctx = [mx.cpu()]
|
||||
print('use cpu')
|
||||
else:
|
||||
print('gpu num:', len(ctx))
|
||||
prefix = args.prefix
|
||||
prefix_dir = os.path.dirname(prefix)
|
||||
if not os.path.exists(prefix_dir):
|
||||
os.makedirs(prefix_dir)
|
||||
end_epoch = args.end_epoch
|
||||
args.ctx_num = len(ctx)
|
||||
args.num_layers = int(args.network[1:])
|
||||
print('num_layers', args.num_layers)
|
||||
if args.per_batch_size == 0:
|
||||
args.per_batch_size = 128
|
||||
args.batch_size = args.per_batch_size * args.ctx_num
|
||||
args.rescale_threshold = 0
|
||||
args.image_channel = 3
|
||||
|
||||
data_dir_list = args.data_dir.split(',')
|
||||
assert len(data_dir_list) == 1
|
||||
data_dir = data_dir_list[0]
|
||||
path_imgrec = None
|
||||
path_imglist = None
|
||||
image_size = [int(x) for x in args.image_size.split(',')]
|
||||
assert len(image_size) == 2
|
||||
assert image_size[0] == image_size[1]
|
||||
args.image_h = image_size[0]
|
||||
args.image_w = image_size[1]
|
||||
print('image_size', image_size)
|
||||
path_imgrec = os.path.join(data_dir, "train.rec")
|
||||
path_imgrec_val = os.path.join(data_dir, "val.rec")
|
||||
|
||||
print('Called with argument:', args)
|
||||
data_shape = (args.image_channel, image_size[0], image_size[1])
|
||||
mean = None
|
||||
|
||||
begin_epoch = 0
|
||||
base_lr = args.lr
|
||||
base_wd = args.wd
|
||||
base_mom = args.mom
|
||||
if len(args.pretrained) == 0:
|
||||
arg_params = None
|
||||
aux_params = None
|
||||
sym, arg_params, aux_params = get_symbol(args, arg_params, aux_params)
|
||||
else:
|
||||
vec = args.pretrained.split(',')
|
||||
print('loading', vec)
|
||||
_, arg_params, aux_params = mx.model.load_checkpoint(
|
||||
vec[0], int(vec[1]))
|
||||
sym, arg_params, aux_params = get_symbol(args, arg_params, aux_params)
|
||||
|
||||
#label_name = 'softmax_label'
|
||||
#label_shape = (args.batch_size,)
|
||||
model = mx.mod.Module(
|
||||
context=ctx,
|
||||
symbol=sym,
|
||||
)
|
||||
val_dataiter = None
|
||||
|
||||
train_dataiter = FaceImageIter(
|
||||
batch_size=args.batch_size,
|
||||
data_shape=data_shape,
|
||||
path_imgrec=path_imgrec,
|
||||
shuffle=True,
|
||||
rand_mirror=args.rand_mirror,
|
||||
mean=mean,
|
||||
cutoff=args.cutoff,
|
||||
color_jittering=args.color,
|
||||
)
|
||||
val_dataiter = FaceImageIter(
|
||||
batch_size=args.batch_size,
|
||||
data_shape=data_shape,
|
||||
path_imgrec=path_imgrec_val,
|
||||
shuffle=False,
|
||||
rand_mirror=False,
|
||||
mean=mean,
|
||||
)
|
||||
|
||||
metric = mx.metric.CompositeEvalMetric(
|
||||
[AccMetric(), MAEMetric(), CUMMetric()])
|
||||
|
||||
if args.network[0] == 'r' or args.network[0] == 'y':
|
||||
initializer = mx.init.Xavier(rnd_type='gaussian',
|
||||
factor_type="out",
|
||||
magnitude=2) #resnet style
|
||||
elif args.network[0] == 'i' or args.network[0] == 'x':
|
||||
initializer = mx.init.Xavier(rnd_type='gaussian',
|
||||
factor_type="in",
|
||||
magnitude=2) #inception
|
||||
else:
|
||||
initializer = mx.init.Xavier(rnd_type='uniform',
|
||||
factor_type="in",
|
||||
magnitude=2)
|
||||
_rescale = 1.0 / args.ctx_num
|
||||
opt = optimizer.SGD(learning_rate=base_lr,
|
||||
momentum=base_mom,
|
||||
wd=base_wd,
|
||||
rescale_grad=_rescale)
|
||||
#opt = optimizer.Nadam(learning_rate=base_lr, wd=base_wd, rescale_grad=_rescale)
|
||||
som = 20
|
||||
_cb = mx.callback.Speedometer(args.batch_size, som)
|
||||
lr_steps = [int(x) for x in args.lr_steps.split(',')]
|
||||
|
||||
global_step = [0]
|
||||
|
||||
def _batch_callback(param):
|
||||
_cb(param)
|
||||
global_step[0] += 1
|
||||
mbatch = global_step[0]
|
||||
for _lr in lr_steps:
|
||||
if mbatch == _lr:
|
||||
opt.lr *= 0.1
|
||||
print('lr change to', opt.lr)
|
||||
break
|
||||
if mbatch % 1000 == 0:
|
||||
print('lr-batch-epoch:', opt.lr, param.nbatch, param.epoch)
|
||||
if mbatch == lr_steps[-1]:
|
||||
arg, aux = model.get_params()
|
||||
all_layers = model.symbol.get_internals()
|
||||
_sym = all_layers['fc1_output']
|
||||
mx.model.save_checkpoint(args.prefix, 0, _sym, arg, aux)
|
||||
sys.exit(0)
|
||||
|
||||
epoch_cb = None
|
||||
train_dataiter = mx.io.PrefetchingIter(train_dataiter)
|
||||
print('start fitting')
|
||||
|
||||
model.fit(
|
||||
train_dataiter,
|
||||
begin_epoch=begin_epoch,
|
||||
num_epoch=end_epoch,
|
||||
eval_data=val_dataiter,
|
||||
eval_metric=metric,
|
||||
kvstore='device',
|
||||
optimizer=opt,
|
||||
#optimizer_params = optimizer_params,
|
||||
initializer=initializer,
|
||||
arg_params=arg_params,
|
||||
aux_params=aux_params,
|
||||
allow_missing=True,
|
||||
batch_end_callback=_batch_callback,
|
||||
epoch_end_callback=epoch_cb)
|
||||
|
||||
|
||||
def main():
|
||||
#time.sleep(3600*6.5)
|
||||
global args
|
||||
args = parse_args()
|
||||
train_net(args)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -1,4 +1,4 @@
|
||||
## Python package of insightface README
|
||||
## Python package
|
||||
|
||||
|
||||
For insightface pip-package <= 0.1.5, we use MXNet as inference backend, please download all models from [onedrive](https://1drv.ms/u/s!AswpsDO2toNKrUy0VktHTWgIQ0bn?e=UEF7C4), and put them all under `~/.insightface/models/` directory.
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 126 KiB After Width: | Height: | Size: 126 KiB |
@@ -82,4 +82,14 @@ class ArcFaceONNX:
|
||||
sim = np.dot(feat1, feat2) / (norm(feat1) * norm(feat2))
|
||||
return sim
|
||||
|
||||
def forward(self, imgs):
|
||||
if not isinstance(imgs, list):
|
||||
imgs = [imgs]
|
||||
input_size = self.input_size
|
||||
|
||||
blob = cv2.dnn.blobFromImages(imgs, 1.0 / self.input_std, input_size,
|
||||
(self.input_mean, self.input_mean, self.input_mean), swapRB=True)
|
||||
net_out = self.session.run(self.output_names, {self.input_name: blob})[0]
|
||||
return net_out
|
||||
|
||||
|
||||
|
||||
@@ -1,24 +1,46 @@
|
||||
## Angular Margin Loss for Deep Face Recognition
|
||||
## Face Recognition
|
||||
|
||||
### Citation
|
||||
|
||||
If you find this project useful in your research, please consider to cite the following related papers:
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/custom/logo3.jpg" width="240"/>
|
||||
</div>
|
||||
|
||||
```
|
||||
|
||||
@inproceedings{deng2019arcface,
|
||||
title={Arcface: Additive angular margin loss for deep face recognition},
|
||||
author={Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos},
|
||||
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
|
||||
pages={4690--4699},
|
||||
year={2019}
|
||||
}
|
||||
## Introduction
|
||||
|
||||
These are the face recognition methods of [InsightFace](https://insightface.ai)
|
||||
|
||||
|
||||
<div align="left">
|
||||
<img src="https://insightface.ai/assets/img/github/facerecognitionfromvideo.PNG" width="600"/>
|
||||
</div>
|
||||
|
||||
|
||||
### Datasets
|
||||
|
||||
Please refer to [datasets](_datasets_) page for the details of face recognition datasets used for training and evaluation.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Please refer to [evaluation](_evaluation_) page for the details of face recognition evaluation.
|
||||
|
||||
|
||||
## Methods
|
||||
|
||||
|
||||
Supported methods:
|
||||
|
||||
- [x] [ArcFace_mxnet (CVPR'2019)](arcface_mxnet)
|
||||
- [x] [ArcFace_torch (CVPR'2019)](arcface_torch)
|
||||
- [x] [SubCenter ArcFace (ECCV'2020)](subcenter_arcface)
|
||||
- [x] [PartialFC_mxnet (Arxiv'2020)](partial_fc)
|
||||
- [x] [PartialFC_torch (Arxiv'2020)](arcface_torch)
|
||||
- [x] [VPL (CVPR'2021)](vpl)
|
||||
- [x] [OneFlow_face](oneflow_face)
|
||||
|
||||
|
||||
## Contributing
|
||||
|
||||
We appreciate all contributions to improve the face recognition model zoo of InsightFace.
|
||||
|
||||
@inproceedings{deng2020subcenter,
|
||||
title={Sub-center ArcFace: Boosting Face Recognition by Large-scale Noisy Web Faces},
|
||||
author={Deng, Jiankang and Guo, Jia and Liu, Tongliang and Gong, Mingming and Zafeiriou, Stefanos},
|
||||
booktitle={Proceedings of the IEEE Conference on European Conference on Computer Vision},
|
||||
year={2020}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
24
recognition/_datasets_/README.md
Normal file
24
recognition/_datasets_/README.md
Normal file
@@ -0,0 +1,24 @@
|
||||
## Angular Margin Loss for Deep Face Recognition
|
||||
|
||||
### Citation
|
||||
|
||||
If you find this project useful in your research, please consider to cite the following related papers:
|
||||
|
||||
```
|
||||
|
||||
@inproceedings{deng2019arcface,
|
||||
title={Arcface: Additive angular margin loss for deep face recognition},
|
||||
author={Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos},
|
||||
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
|
||||
pages={4690--4699},
|
||||
year={2019}
|
||||
}
|
||||
|
||||
@inproceedings{deng2020subcenter,
|
||||
title={Sub-center ArcFace: Boosting Face Recognition by Large-scale Noisy Web Faces},
|
||||
author={Deng, Jiankang and Guo, Jia and Liu, Tongliang and Gong, Mingming and Zafeiriou, Stefanos},
|
||||
booktitle={Proceedings of the IEEE Conference on European Conference on Computer Vision},
|
||||
year={2020}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -1,6 +1,6 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
python -u IJB_11.py --model-prefix ./pretrained_models/r100-arcface/model --model-epoch 1 --gpu 0 --target IJBC --job arcface > ijbc_11.log 2>&1 &
|
||||
python -u ijb_11.py --model-prefix ./pretrained_models/r100-arcface/model --model-epoch 1 --gpu 0 --target IJBC --job arcface > ijbc_11.log 2>&1 &
|
||||
|
||||
python -u IJB_1N.py --model-prefix ./pretrained_models/r100-arcface/model --model-epoch 1 --gpu 0 --target IJBB --job arcface > ijbb_1n.log 2>&1 &
|
||||
python -u ijb_1n.py --model-prefix ./pretrained_models/r100-arcface/model --model-epoch 1 --gpu 0 --target IJBB --job arcface > ijbb_1n.log 2>&1 &
|
||||
|
||||
267
recognition/_evaluation_/ijb/ijb_onnx.py
Normal file
267
recognition/_evaluation_/ijb/ijb_onnx.py
Normal file
@@ -0,0 +1,267 @@
|
||||
import argparse
|
||||
import os
|
||||
import pickle
|
||||
import timeit
|
||||
|
||||
import cv2
|
||||
import mxnet as mx
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
import prettytable
|
||||
import skimage.transform
|
||||
from sklearn.metrics import roc_curve
|
||||
from sklearn.preprocessing import normalize
|
||||
import insightface
|
||||
from insightface.model_zoo import ArcFaceONNX
|
||||
|
||||
|
||||
SRC = np.array(
|
||||
[
|
||||
[30.2946, 51.6963],
|
||||
[65.5318, 51.5014],
|
||||
[48.0252, 71.7366],
|
||||
[33.5493, 92.3655],
|
||||
[62.7299, 92.2041]]
|
||||
, dtype=np.float32)
|
||||
SRC[:, 0] += 8.0
|
||||
|
||||
|
||||
class AlignedDataSet(mx.gluon.data.Dataset):
|
||||
def __init__(self, root, lines, align=True):
|
||||
self.lines = lines
|
||||
self.root = root
|
||||
self.align = align
|
||||
|
||||
def __len__(self):
|
||||
return len(self.lines)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
each_line = self.lines[idx]
|
||||
name_lmk_score = each_line.strip().split(' ')
|
||||
name = os.path.join(self.root, name_lmk_score[0])
|
||||
img = cv2.cvtColor(cv2.imread(name), cv2.COLOR_BGR2RGB)
|
||||
landmark5 = np.array([float(x) for x in name_lmk_score[1:-1]], dtype=np.float32).reshape((5, 2))
|
||||
st = skimage.transform.SimilarityTransform()
|
||||
st.estimate(landmark5, SRC)
|
||||
img = cv2.warpAffine(img, st.params[0:2, :], (112, 112), borderValue=0.0)
|
||||
img_1 = np.expand_dims(img, 0)
|
||||
img_2 = np.expand_dims(np.fliplr(img), 0)
|
||||
output = np.concatenate((img_1, img_2), axis=0).astype(np.float32)
|
||||
output = np.transpose(output, (0, 3, 1, 2))
|
||||
output = mx.nd.array(output)
|
||||
return output
|
||||
|
||||
|
||||
def extract(model_file, dataset):
|
||||
model = ArcFaceONNX(model_file=model_file)
|
||||
model.check()
|
||||
feat_mat = np.zeros(shape=(len(dataset), 2 * model.feat_dim))
|
||||
|
||||
def batchify_fn(data):
|
||||
return mx.nd.concat(*data, dim=0)
|
||||
|
||||
data_loader = mx.gluon.data.DataLoader(
|
||||
dataset, 128, last_batch='keep', num_workers=4,
|
||||
thread_pool=True, prefetch=16, batchify_fn=batchify_fn)
|
||||
num_iter = 0
|
||||
for batch in data_loader:
|
||||
batch = batch.asnumpy()
|
||||
feat = model.forward(batch)
|
||||
feat = np.reshape(feat, (-1, model.feat_dim * 2))
|
||||
feat_mat[128 * num_iter: 128 * num_iter + feat.shape[0], :] = feat
|
||||
num_iter += 1
|
||||
if num_iter % 50 == 0:
|
||||
print(num_iter)
|
||||
return feat_mat
|
||||
|
||||
|
||||
def read_template_media_list(path):
|
||||
ijb_meta = pd.read_csv(path, sep=' ', header=None).values
|
||||
templates = ijb_meta[:, 1].astype(np.int)
|
||||
medias = ijb_meta[:, 2].astype(np.int)
|
||||
return templates, medias
|
||||
|
||||
|
||||
def read_template_pair_list(path):
|
||||
pairs = pd.read_csv(path, sep=' ', header=None).values
|
||||
t1 = pairs[:, 0].astype(np.int)
|
||||
t2 = pairs[:, 1].astype(np.int)
|
||||
label = pairs[:, 2].astype(np.int)
|
||||
return t1, t2, label
|
||||
|
||||
|
||||
def read_image_feature(path):
|
||||
with open(path, 'rb') as fid:
|
||||
img_feats = pickle.load(fid)
|
||||
return img_feats
|
||||
|
||||
|
||||
def image2template_feature(img_feats=None,
|
||||
templates=None,
|
||||
medias=None):
|
||||
unique_templates = np.unique(templates)
|
||||
template_feats = np.zeros((len(unique_templates), img_feats.shape[1]))
|
||||
for count_template, uqt in enumerate(unique_templates):
|
||||
(ind_t,) = np.where(templates == uqt)
|
||||
face_norm_feats = img_feats[ind_t]
|
||||
face_medias = medias[ind_t]
|
||||
unique_medias, unique_media_counts = np.unique(face_medias, return_counts=True)
|
||||
media_norm_feats = []
|
||||
for u, ct in zip(unique_medias, unique_media_counts):
|
||||
(ind_m,) = np.where(face_medias == u)
|
||||
if ct == 1:
|
||||
media_norm_feats += [face_norm_feats[ind_m]]
|
||||
else: # image features from the same video will be aggregated into one feature
|
||||
media_norm_feats += [np.mean(face_norm_feats[ind_m], axis=0, keepdims=True), ]
|
||||
media_norm_feats = np.array(media_norm_feats)
|
||||
template_feats[count_template] = np.sum(media_norm_feats, axis=0)
|
||||
if count_template % 2000 == 0:
|
||||
print('Finish Calculating {} template features.'.format(
|
||||
count_template))
|
||||
template_norm_feats = normalize(template_feats)
|
||||
return template_norm_feats, unique_templates
|
||||
|
||||
|
||||
def verification(template_norm_feats=None,
|
||||
unique_templates=None,
|
||||
p1=None,
|
||||
p2=None):
|
||||
template2id = np.zeros((max(unique_templates) + 1, 1), dtype=int)
|
||||
for count_template, uqt in enumerate(unique_templates):
|
||||
template2id[uqt] = count_template
|
||||
score = np.zeros((len(p1),))
|
||||
total_pairs = np.array(range(len(p1)))
|
||||
batchsize = 100000
|
||||
sublists = [total_pairs[i: i + batchsize] for i in range(0, len(p1), batchsize)]
|
||||
total_sublists = len(sublists)
|
||||
for c, s in enumerate(sublists):
|
||||
feat1 = template_norm_feats[template2id[p1[s]]]
|
||||
feat2 = template_norm_feats[template2id[p2[s]]]
|
||||
similarity_score = np.sum(feat1 * feat2, -1)
|
||||
score[s] = similarity_score.flatten()
|
||||
if c % 10 == 0:
|
||||
print('Finish {}/{} pairs.'.format(c, total_sublists))
|
||||
return score
|
||||
|
||||
|
||||
def verification2(template_norm_feats=None,
|
||||
unique_templates=None,
|
||||
p1=None,
|
||||
p2=None):
|
||||
template2id = np.zeros((max(unique_templates) + 1, 1), dtype=int)
|
||||
for count_template, uqt in enumerate(unique_templates):
|
||||
template2id[uqt] = count_template
|
||||
score = np.zeros((len(p1),)) # save cosine distance between pairs
|
||||
total_pairs = np.array(range(len(p1)))
|
||||
batchsize = 100000 # small batchsize instead of all pairs in one batch due to the memory limiation
|
||||
sublists = [total_pairs[i:i + batchsize] for i in range(0, len(p1), batchsize)]
|
||||
total_sublists = len(sublists)
|
||||
for c, s in enumerate(sublists):
|
||||
feat1 = template_norm_feats[template2id[p1[s]]]
|
||||
feat2 = template_norm_feats[template2id[p2[s]]]
|
||||
similarity_score = np.sum(feat1 * feat2, -1)
|
||||
score[s] = similarity_score.flatten()
|
||||
if c % 10 == 0:
|
||||
print('Finish {}/{} pairs.'.format(c, total_sublists))
|
||||
return score
|
||||
|
||||
|
||||
def main(args):
|
||||
use_norm_score = True # if Ture, TestMode(N1)
|
||||
use_detector_score = True # if Ture, TestMode(D1)
|
||||
use_flip_test = True # if Ture, TestMode(F1)
|
||||
assert args.target == 'IJBC' or args.target == 'IJBB'
|
||||
|
||||
start = timeit.default_timer()
|
||||
templates, medias = read_template_media_list(
|
||||
os.path.join('%s/meta' % args.image_path, '%s_face_tid_mid.txt' % args.target.lower()))
|
||||
stop = timeit.default_timer()
|
||||
print('Time: %.2f s. ' % (stop - start))
|
||||
|
||||
start = timeit.default_timer()
|
||||
p1, p2, label = read_template_pair_list(
|
||||
os.path.join('%s/meta' % args.image_path,
|
||||
'%s_template_pair_label.txt' % args.target.lower()))
|
||||
stop = timeit.default_timer()
|
||||
print('Time: %.2f s. ' % (stop - start))
|
||||
|
||||
start = timeit.default_timer()
|
||||
img_path = '%s/loose_crop' % args.image_path
|
||||
img_list_path = '%s/meta/%s_name_5pts_score.txt' % (args.image_path, args.target.lower())
|
||||
img_list = open(img_list_path)
|
||||
files = img_list.readlines()
|
||||
dataset = AlignedDataSet(root=img_path, lines=files, align=True)
|
||||
img_feats = extract(args.model_file, dataset)
|
||||
|
||||
faceness_scores = []
|
||||
for each_line in files:
|
||||
name_lmk_score = each_line.split()
|
||||
faceness_scores.append(name_lmk_score[-1])
|
||||
faceness_scores = np.array(faceness_scores).astype(np.float32)
|
||||
stop = timeit.default_timer()
|
||||
print('Time: %.2f s. ' % (stop - start))
|
||||
print('Feature Shape: ({} , {}) .'.format(img_feats.shape[0], img_feats.shape[1]))
|
||||
start = timeit.default_timer()
|
||||
|
||||
if use_flip_test:
|
||||
img_input_feats = img_feats[:, 0:img_feats.shape[1] // 2] + img_feats[:, img_feats.shape[1] // 2:]
|
||||
else:
|
||||
img_input_feats = img_feats[:, 0:img_feats.shape[1] // 2]
|
||||
|
||||
if use_norm_score:
|
||||
img_input_feats = img_input_feats
|
||||
else:
|
||||
img_input_feats = img_input_feats / np.sqrt(np.sum(img_input_feats ** 2, -1, keepdims=True))
|
||||
|
||||
if use_detector_score:
|
||||
print(img_input_feats.shape, faceness_scores.shape)
|
||||
img_input_feats = img_input_feats * faceness_scores[:, np.newaxis]
|
||||
else:
|
||||
img_input_feats = img_input_feats
|
||||
|
||||
template_norm_feats, unique_templates = image2template_feature(
|
||||
img_input_feats, templates, medias)
|
||||
stop = timeit.default_timer()
|
||||
print('Time: %.2f s. ' % (stop - start))
|
||||
|
||||
start = timeit.default_timer()
|
||||
score = verification(template_norm_feats, unique_templates, p1, p2)
|
||||
stop = timeit.default_timer()
|
||||
print('Time: %.2f s. ' % (stop - start))
|
||||
save_path = os.path.join(args.result_dir, "{}_result".format(args.target))
|
||||
if not os.path.exists(save_path):
|
||||
os.makedirs(save_path)
|
||||
score_save_file = os.path.join(save_path, "{}.npy".format(args.model_file.split('/')[-1]))
|
||||
np.save(score_save_file, score)
|
||||
files = [score_save_file]
|
||||
methods = []
|
||||
scores = []
|
||||
for file in files:
|
||||
methods.append(os.path.basename(file))
|
||||
scores.append(np.load(file))
|
||||
methods = np.array(methods)
|
||||
scores = dict(zip(methods, scores))
|
||||
x_labels = [10 ** -6, 10 ** -5, 10 ** -4, 10 ** -3, 10 ** -2, 10 ** -1]
|
||||
tpr_fpr_table = prettytable.PrettyTable(['Methods'] + [str(x) for x in x_labels])
|
||||
for method in methods:
|
||||
fpr, tpr, _ = roc_curve(label, scores[method])
|
||||
fpr = np.flipud(fpr)
|
||||
tpr = np.flipud(tpr)
|
||||
tpr_fpr_row = []
|
||||
tpr_fpr_row.append("%s-%s" % (method, args.target))
|
||||
for fpr_iter in np.arange(len(x_labels)):
|
||||
_, min_index = min(
|
||||
list(zip(abs(fpr - x_labels[fpr_iter]), range(len(fpr)))))
|
||||
tpr_fpr_row.append('%.2f' % (tpr[min_index] * 100))
|
||||
tpr_fpr_table.add_row(tpr_fpr_row)
|
||||
print(tpr_fpr_table)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser(description='do onnx ijb test')
|
||||
# general
|
||||
parser.add_argument('--model-file', default='', help='path to onnx model.')
|
||||
parser.add_argument('--image-path', default='', type=str, help='')
|
||||
parser.add_argument('--result-dir', default='.', type=str, help='')
|
||||
parser.add_argument('--target', default='IJBC', type=str, help='target, set to IJBC or IJBB')
|
||||
main(parser.parse_args())
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user