diff --git a/README.md b/README.md
index c589ea5..a544815 100644
--- a/README.md
+++ b/README.md
@@ -27,6 +27,7 @@
- [Adaptive Token Sampling](#adaptive-token-sampling)
- [Patch Merger](#patch-merger)
- [Vision Transformer for Small Datasets](#vision-transformer-for-small-datasets)
+- [Parallel ViT](#parallel-vit)
- [Dino](#dino)
- [Accessing Attention](#accessing-attention)
- [Research Ideas](#research-ideas)
@@ -240,6 +241,7 @@ preds = v(img) # (1, 1000)
```
## CCT
+
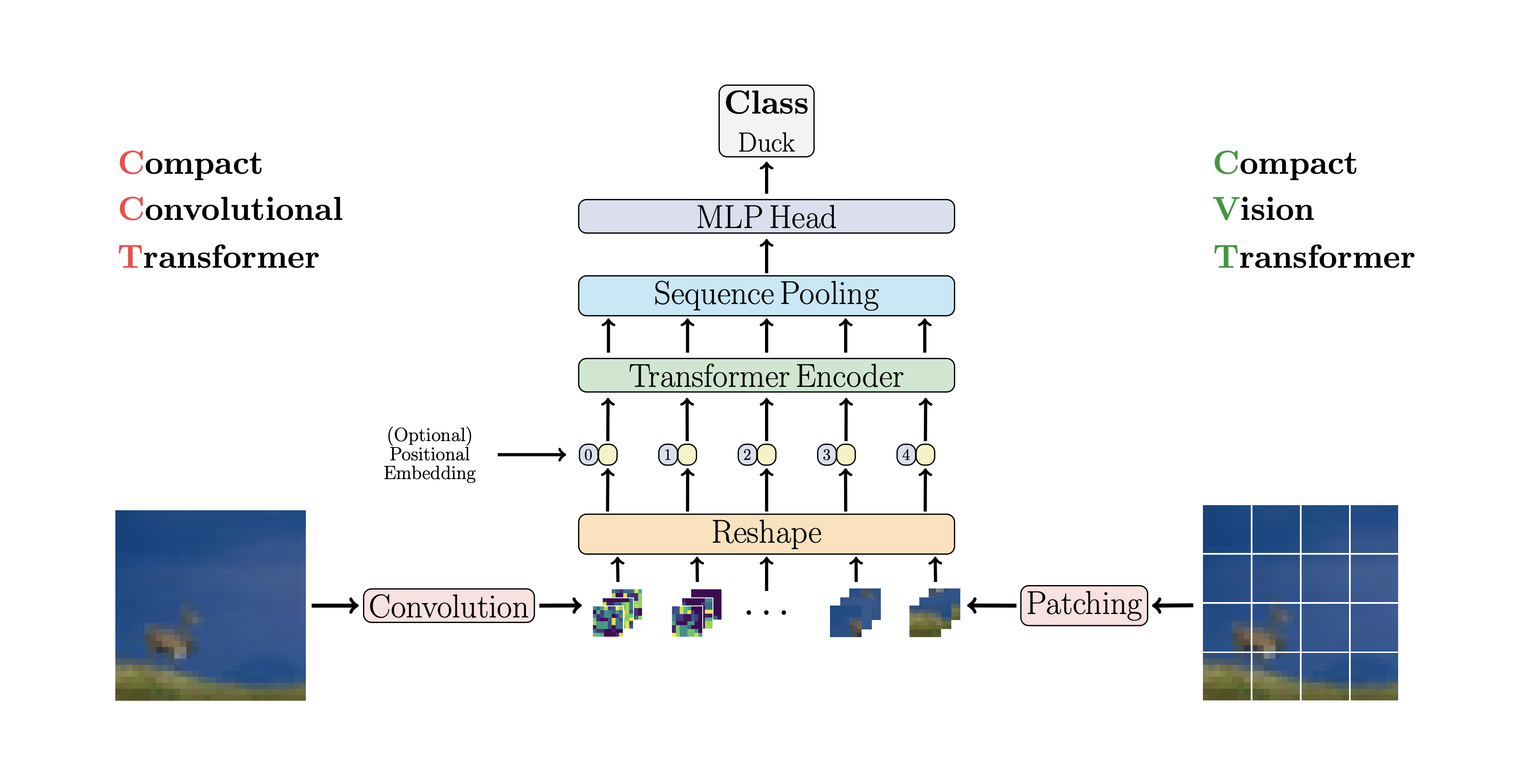 CCT proposes compact transformers
@@ -866,6 +868,37 @@ img = torch.randn(4, 3, 256, 256)
tokens = spt(img) # (4, 256, 1024)
```
+## Parallel ViT
+
+
CCT proposes compact transformers
@@ -866,6 +868,37 @@ img = torch.randn(4, 3, 256, 256)
tokens = spt(img) # (4, 256, 1024)
```
+## Parallel ViT
+
+ +
+This paper propose parallelizing multiple attention and feedforward blocks per layer (2 blocks), claiming that it is easier to train without loss of performance.
+
+You can try this variant as follows
+
+```python
+import torch
+from vit_pytorch.parallel_vit import ViT
+
+v = ViT(
+ image_size = 256,
+ patch_size = 16,
+ num_classes = 1000,
+ dim = 1024,
+ depth = 6,
+ heads = 8,
+ mlp_dim = 2048,
+ num_parallel_branches = 2, # in paper, they claimed 2 was optimal
+ dropout = 0.1,
+ emb_dropout = 0.1
+)
+
+img = torch.randn(4, 3, 256, 256)
+
+preds = v(img) # (4, 1000)
+```
+
+
## Dino
+
+This paper propose parallelizing multiple attention and feedforward blocks per layer (2 blocks), claiming that it is easier to train without loss of performance.
+
+You can try this variant as follows
+
+```python
+import torch
+from vit_pytorch.parallel_vit import ViT
+
+v = ViT(
+ image_size = 256,
+ patch_size = 16,
+ num_classes = 1000,
+ dim = 1024,
+ depth = 6,
+ heads = 8,
+ mlp_dim = 2048,
+ num_parallel_branches = 2, # in paper, they claimed 2 was optimal
+ dropout = 0.1,
+ emb_dropout = 0.1
+)
+
+img = torch.randn(4, 3, 256, 256)
+
+preds = v(img) # (4, 1000)
+```
+
+
## Dino
 @@ -1396,6 +1429,14 @@ Coming from computer vision and new to transformers? Here are some resources tha
}
```
+```bibtex
+@inproceedings{Touvron2022ThreeTE,
+ title = {Three things everyone should know about Vision Transformers},
+ author = {Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou},
+ year = {2022}
+}
+```
+
```bibtex
@misc{vaswani2017attention,
title = {Attention Is All You Need},
diff --git a/images/parallel-vit.png b/images/parallel-vit.png
new file mode 100644
index 0000000..4a84741
Binary files /dev/null and b/images/parallel-vit.png differ
diff --git a/setup.py b/setup.py
index 4eb67ad..fcfc8c6 100644
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,7 @@ from setuptools import setup, find_packages
setup(
name = 'vit-pytorch',
packages = find_packages(exclude=['examples']),
- version = '0.28.2',
+ version = '0.29.0',
license='MIT',
description = 'Vision Transformer (ViT) - Pytorch',
author = 'Phil Wang',
diff --git a/vit_pytorch/parallel_vit.py b/vit_pytorch/parallel_vit.py
new file mode 100644
index 0000000..62c574b
--- /dev/null
+++ b/vit_pytorch/parallel_vit.py
@@ -0,0 +1,137 @@
+import torch
+from torch import nn
+
+from einops import rearrange, repeat
+from einops.layers.torch import Rearrange
+
+# helpers
+
+def pair(t):
+ return t if isinstance(t, tuple) else (t, t)
+
+# classes
+
+class Parallel(nn.Module):
+ def __init__(self, *fns):
+ super().__init__()
+ self.fns = nn.ModuleList(fns)
+
+ def forward(self, x):
+ return sum([fn(x) for fn in self.fns])
+
+class PreNorm(nn.Module):
+ def __init__(self, dim, fn):
+ super().__init__()
+ self.norm = nn.LayerNorm(dim)
+ self.fn = fn
+ def forward(self, x, **kwargs):
+ return self.fn(self.norm(x), **kwargs)
+
+class FeedForward(nn.Module):
+ def __init__(self, dim, hidden_dim, dropout = 0.):
+ super().__init__()
+ self.net = nn.Sequential(
+ nn.Linear(dim, hidden_dim),
+ nn.GELU(),
+ nn.Dropout(dropout),
+ nn.Linear(hidden_dim, dim),
+ nn.Dropout(dropout)
+ )
+ def forward(self, x):
+ return self.net(x)
+
+class Attention(nn.Module):
+ def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
+ super().__init__()
+ inner_dim = dim_head * heads
+ project_out = not (heads == 1 and dim_head == dim)
+
+ self.heads = heads
+ self.scale = dim_head ** -0.5
+
+ self.attend = nn.Softmax(dim = -1)
+ self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
+
+ self.to_out = nn.Sequential(
+ nn.Linear(inner_dim, dim),
+ nn.Dropout(dropout)
+ ) if project_out else nn.Identity()
+
+ def forward(self, x):
+ qkv = self.to_qkv(x).chunk(3, dim = -1)
+ q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
+
+ dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
+
+ attn = self.attend(dots)
+
+ out = torch.matmul(attn, v)
+ out = rearrange(out, 'b h n d -> b n (h d)')
+ return self.to_out(out)
+
+class Transformer(nn.Module):
+ def __init__(self, dim, depth, heads, dim_head, mlp_dim, num_parallel_branches = 2, dropout = 0.):
+ super().__init__()
+ self.layers = nn.ModuleList([])
+
+ attn_block = lambda: PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))
+ ff_block = lambda: PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
+
+ for _ in range(depth):
+ self.layers.append(nn.ModuleList([
+ Parallel(*[attn_block() for _ in range(num_parallel_branches)]),
+ Parallel(*[ff_block() for _ in range(num_parallel_branches)]),
+ ]))
+
+ def forward(self, x):
+ for attns, ffs in self.layers:
+ x = attns(x) + x
+ x = ffs(x) + x
+ return x
+
+class ViT(nn.Module):
+ def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', num_parallel_branches = 2, channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
+ super().__init__()
+ image_height, image_width = pair(image_size)
+ patch_height, patch_width = pair(patch_size)
+
+ assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
+
+ num_patches = (image_height // patch_height) * (image_width // patch_width)
+ patch_dim = channels * patch_height * patch_width
+ assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
+
+ self.to_patch_embedding = nn.Sequential(
+ Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
+ nn.Linear(patch_dim, dim),
+ )
+
+ self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
+ self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
+ self.dropout = nn.Dropout(emb_dropout)
+
+ self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, num_parallel_branches, dropout)
+
+ self.pool = pool
+ self.to_latent = nn.Identity()
+
+ self.mlp_head = nn.Sequential(
+ nn.LayerNorm(dim),
+ nn.Linear(dim, num_classes)
+ )
+
+ def forward(self, img):
+ x = self.to_patch_embedding(img)
+ b, n, _ = x.shape
+
+ cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
+ x = torch.cat((cls_tokens, x), dim=1)
+ x += self.pos_embedding[:, :(n + 1)]
+ x = self.dropout(x)
+
+ x = self.transformer(x)
+
+ x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
+
+ x = self.to_latent(x)
+ return self.mlp_head(x)
@@ -1396,6 +1429,14 @@ Coming from computer vision and new to transformers? Here are some resources tha
}
```
+```bibtex
+@inproceedings{Touvron2022ThreeTE,
+ title = {Three things everyone should know about Vision Transformers},
+ author = {Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou},
+ year = {2022}
+}
+```
+
```bibtex
@misc{vaswani2017attention,
title = {Attention Is All You Need},
diff --git a/images/parallel-vit.png b/images/parallel-vit.png
new file mode 100644
index 0000000..4a84741
Binary files /dev/null and b/images/parallel-vit.png differ
diff --git a/setup.py b/setup.py
index 4eb67ad..fcfc8c6 100644
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,7 @@ from setuptools import setup, find_packages
setup(
name = 'vit-pytorch',
packages = find_packages(exclude=['examples']),
- version = '0.28.2',
+ version = '0.29.0',
license='MIT',
description = 'Vision Transformer (ViT) - Pytorch',
author = 'Phil Wang',
diff --git a/vit_pytorch/parallel_vit.py b/vit_pytorch/parallel_vit.py
new file mode 100644
index 0000000..62c574b
--- /dev/null
+++ b/vit_pytorch/parallel_vit.py
@@ -0,0 +1,137 @@
+import torch
+from torch import nn
+
+from einops import rearrange, repeat
+from einops.layers.torch import Rearrange
+
+# helpers
+
+def pair(t):
+ return t if isinstance(t, tuple) else (t, t)
+
+# classes
+
+class Parallel(nn.Module):
+ def __init__(self, *fns):
+ super().__init__()
+ self.fns = nn.ModuleList(fns)
+
+ def forward(self, x):
+ return sum([fn(x) for fn in self.fns])
+
+class PreNorm(nn.Module):
+ def __init__(self, dim, fn):
+ super().__init__()
+ self.norm = nn.LayerNorm(dim)
+ self.fn = fn
+ def forward(self, x, **kwargs):
+ return self.fn(self.norm(x), **kwargs)
+
+class FeedForward(nn.Module):
+ def __init__(self, dim, hidden_dim, dropout = 0.):
+ super().__init__()
+ self.net = nn.Sequential(
+ nn.Linear(dim, hidden_dim),
+ nn.GELU(),
+ nn.Dropout(dropout),
+ nn.Linear(hidden_dim, dim),
+ nn.Dropout(dropout)
+ )
+ def forward(self, x):
+ return self.net(x)
+
+class Attention(nn.Module):
+ def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
+ super().__init__()
+ inner_dim = dim_head * heads
+ project_out = not (heads == 1 and dim_head == dim)
+
+ self.heads = heads
+ self.scale = dim_head ** -0.5
+
+ self.attend = nn.Softmax(dim = -1)
+ self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
+
+ self.to_out = nn.Sequential(
+ nn.Linear(inner_dim, dim),
+ nn.Dropout(dropout)
+ ) if project_out else nn.Identity()
+
+ def forward(self, x):
+ qkv = self.to_qkv(x).chunk(3, dim = -1)
+ q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
+
+ dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
+
+ attn = self.attend(dots)
+
+ out = torch.matmul(attn, v)
+ out = rearrange(out, 'b h n d -> b n (h d)')
+ return self.to_out(out)
+
+class Transformer(nn.Module):
+ def __init__(self, dim, depth, heads, dim_head, mlp_dim, num_parallel_branches = 2, dropout = 0.):
+ super().__init__()
+ self.layers = nn.ModuleList([])
+
+ attn_block = lambda: PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))
+ ff_block = lambda: PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
+
+ for _ in range(depth):
+ self.layers.append(nn.ModuleList([
+ Parallel(*[attn_block() for _ in range(num_parallel_branches)]),
+ Parallel(*[ff_block() for _ in range(num_parallel_branches)]),
+ ]))
+
+ def forward(self, x):
+ for attns, ffs in self.layers:
+ x = attns(x) + x
+ x = ffs(x) + x
+ return x
+
+class ViT(nn.Module):
+ def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', num_parallel_branches = 2, channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
+ super().__init__()
+ image_height, image_width = pair(image_size)
+ patch_height, patch_width = pair(patch_size)
+
+ assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
+
+ num_patches = (image_height // patch_height) * (image_width // patch_width)
+ patch_dim = channels * patch_height * patch_width
+ assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
+
+ self.to_patch_embedding = nn.Sequential(
+ Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
+ nn.Linear(patch_dim, dim),
+ )
+
+ self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
+ self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
+ self.dropout = nn.Dropout(emb_dropout)
+
+ self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, num_parallel_branches, dropout)
+
+ self.pool = pool
+ self.to_latent = nn.Identity()
+
+ self.mlp_head = nn.Sequential(
+ nn.LayerNorm(dim),
+ nn.Linear(dim, num_classes)
+ )
+
+ def forward(self, img):
+ x = self.to_patch_embedding(img)
+ b, n, _ = x.shape
+
+ cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
+ x = torch.cat((cls_tokens, x), dim=1)
+ x += self.pos_embedding[:, :(n + 1)]
+ x = self.dropout(x)
+
+ x = self.transformer(x)
+
+ x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
+
+ x = self.to_latent(x)
+ return self.mlp_head(x)