From a73030c9aa1964225dbdc767ff838cdce8d4208b Mon Sep 17 00:00:00 2001
From: Ali Hassani <68103095+alihassanijr@users.noreply.github.com>
Date: Thu, 1 Jul 2021 16:41:27 -0700
Subject: [PATCH] Update README.md
---
README.md | 112 +++++++++++++++++++++++++++---------------------------
1 file changed, 57 insertions(+), 55 deletions(-)
diff --git a/README.md b/README.md
index f0eb1ca..cb84743 100644
--- a/README.md
+++ b/README.md
@@ -62,61 +62,6 @@ Dropout rate.
Embedding dropout rate.
- `pool`: string, either `cls` token pooling or `mean` pooling
-## Distillation
-
- -
-A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
-
-ex. distilling from Resnet50 (or any teacher) to a vision transformer
-
-```python
-import torch
-from torchvision.models import resnet50
-
-from vit_pytorch.distill import DistillableViT, DistillWrapper
-
-teacher = resnet50(pretrained = True)
-
-v = DistillableViT(
- image_size = 256,
- patch_size = 32,
- num_classes = 1000,
- dim = 1024,
- depth = 6,
- heads = 8,
- mlp_dim = 2048,
- dropout = 0.1,
- emb_dropout = 0.1
-)
-
-distiller = DistillWrapper(
- student = v,
- teacher = teacher,
- temperature = 3, # temperature of distillation
- alpha = 0.5, # trade between main loss and distillation loss
- hard = False # whether to use soft or hard distillation
-)
-
-img = torch.randn(2, 3, 256, 256)
-labels = torch.randint(0, 1000, (2,))
-
-loss = distiller(img, labels)
-loss.backward()
-
-# after lots of training above ...
-
-pred = v(img) # (2, 1000)
-```
-
-The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
-
-You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
-
-```python
-v = v.to_vit()
-type(v) #
-```
## CCT
-
-A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
-
-ex. distilling from Resnet50 (or any teacher) to a vision transformer
-
-```python
-import torch
-from torchvision.models import resnet50
-
-from vit_pytorch.distill import DistillableViT, DistillWrapper
-
-teacher = resnet50(pretrained = True)
-
-v = DistillableViT(
- image_size = 256,
- patch_size = 32,
- num_classes = 1000,
- dim = 1024,
- depth = 6,
- heads = 8,
- mlp_dim = 2048,
- dropout = 0.1,
- emb_dropout = 0.1
-)
-
-distiller = DistillWrapper(
- student = v,
- teacher = teacher,
- temperature = 3, # temperature of distillation
- alpha = 0.5, # trade between main loss and distillation loss
- hard = False # whether to use soft or hard distillation
-)
-
-img = torch.randn(2, 3, 256, 256)
-labels = torch.randint(0, 1000, (2,))
-
-loss = distiller(img, labels)
-loss.backward()
-
-# after lots of training above ...
-
-pred = v(img) # (2, 1000)
-```
-
-The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
-
-You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
-
-```python
-v = v.to_vit()
-type(v) #
-```
## CCT
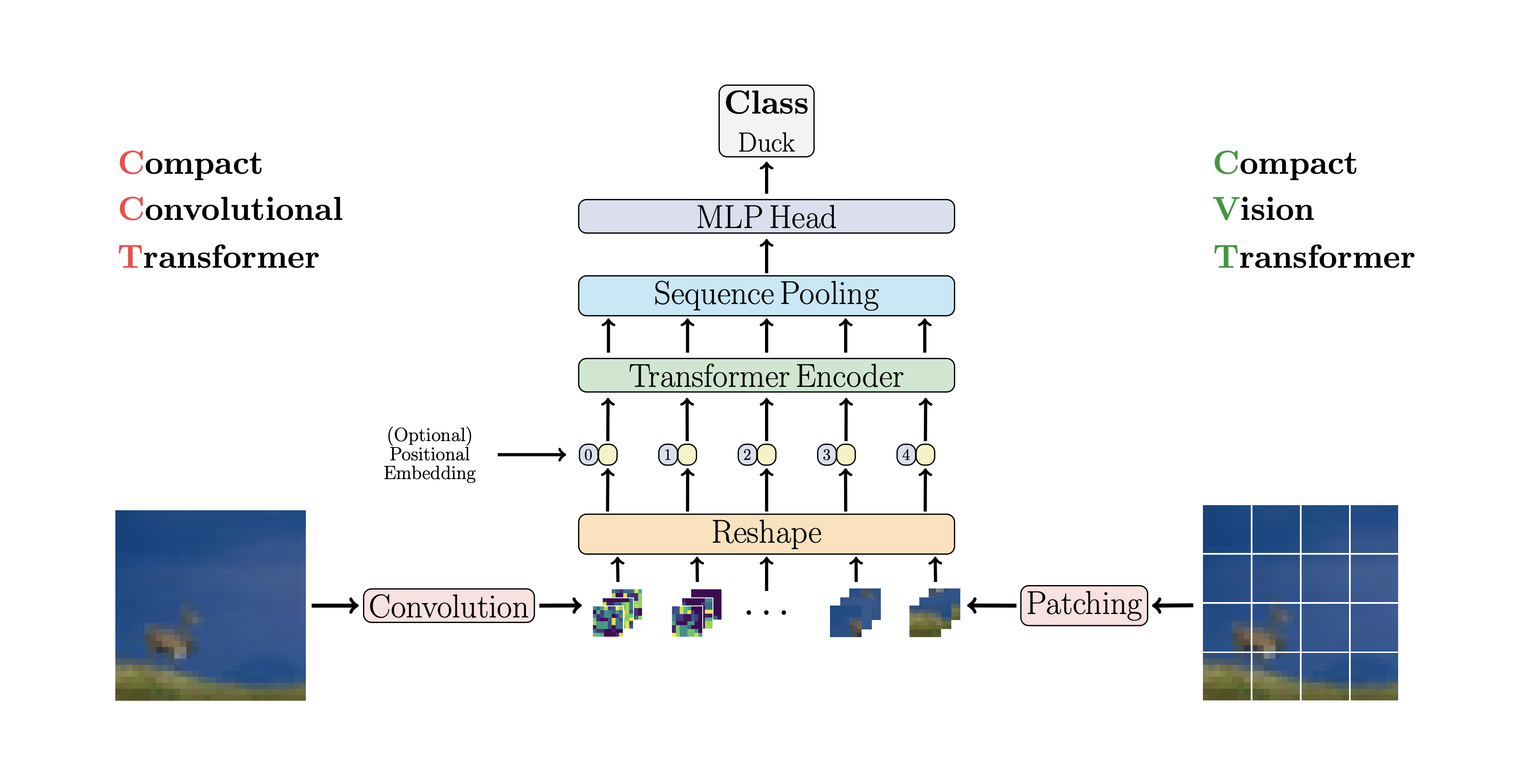 @@ -182,6 +127,63 @@ model = cct_2(
Repository
+## Distillation
+
+
+
+A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
+
+ex. distilling from Resnet50 (or any teacher) to a vision transformer
+
+```python
+import torch
+from torchvision.models import resnet50
+
+from vit_pytorch.distill import DistillableViT, DistillWrapper
+
+teacher = resnet50(pretrained = True)
+
+v = DistillableViT(
+ image_size = 256,
+ patch_size = 32,
+ num_classes = 1000,
+ dim = 1024,
+ depth = 6,
+ heads = 8,
+ mlp_dim = 2048,
+ dropout = 0.1,
+ emb_dropout = 0.1
+)
+
+distiller = DistillWrapper(
+ student = v,
+ teacher = teacher,
+ temperature = 3, # temperature of distillation
+ alpha = 0.5, # trade between main loss and distillation loss
+ hard = False # whether to use soft or hard distillation
+)
+
+img = torch.randn(2, 3, 256, 256)
+labels = torch.randint(0, 1000, (2,))
+
+loss = distiller(img, labels)
+loss.backward()
+
+# after lots of training above ...
+
+pred = v(img) # (2, 1000)
+```
+
+The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
+
+You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
+
+```python
+v = v.to_vit()
+type(v) #
+```
+
+
## Deep ViT
This paper notes that ViT struggles to attend at greater depths (past 12 layers), and suggests mixing the attention of each head post-softmax as a solution, dubbed Re-attention. The results line up with the Talking Heads paper from NLP.
@@ -182,6 +127,63 @@ model = cct_2(
Repository
+## Distillation
+
+
+
+A recent paper has shown that use of a distillation token for distilling knowledge from convolutional nets to vision transformer can yield small and efficient vision transformers. This repository offers the means to do distillation easily.
+
+ex. distilling from Resnet50 (or any teacher) to a vision transformer
+
+```python
+import torch
+from torchvision.models import resnet50
+
+from vit_pytorch.distill import DistillableViT, DistillWrapper
+
+teacher = resnet50(pretrained = True)
+
+v = DistillableViT(
+ image_size = 256,
+ patch_size = 32,
+ num_classes = 1000,
+ dim = 1024,
+ depth = 6,
+ heads = 8,
+ mlp_dim = 2048,
+ dropout = 0.1,
+ emb_dropout = 0.1
+)
+
+distiller = DistillWrapper(
+ student = v,
+ teacher = teacher,
+ temperature = 3, # temperature of distillation
+ alpha = 0.5, # trade between main loss and distillation loss
+ hard = False # whether to use soft or hard distillation
+)
+
+img = torch.randn(2, 3, 256, 256)
+labels = torch.randint(0, 1000, (2,))
+
+loss = distiller(img, labels)
+loss.backward()
+
+# after lots of training above ...
+
+pred = v(img) # (2, 1000)
+```
+
+The `DistillableViT` class is identical to `ViT` except for how the forward pass is handled, so you should be able to load the parameters back to `ViT` after you have completed distillation training.
+
+You can also use the handy `.to_vit` method on the `DistillableViT` instance to get back a `ViT` instance.
+
+```python
+v = v.to_vit()
+type(v) #
+```
+
+
## Deep ViT
This paper notes that ViT struggles to attend at greater depths (past 12 layers), and suggests mixing the attention of each head post-softmax as a solution, dubbed Re-attention. The results line up with the Talking Heads paper from NLP.